

Unraveling Research Population and Sample: Understanding their role in statistical inference
Research population and sample serve as the cornerstones of any scientific inquiry. They hold the power to unlock the mysteries hidden within data. Understanding the dynamics between the research population and sample is crucial for researchers. It ensures the validity, reliability, and generalizability of their findings. In this article, we uncover the profound role of the research population and sample, unveiling their differences and importance that reshapes our understanding of complex phenomena. Ultimately, this empowers researchers to make informed conclusions and drive meaningful advancements in our respective fields.
Table of Contents
What Is Population?
The research population, also known as the target population, refers to the entire group or set of individuals, objects, or events that possess specific characteristics and are of interest to the researcher. It represents the larger population from which a sample is drawn. The research population is defined based on the research objectives and the specific parameters or attributes under investigation. For example, in a study on the effects of a new drug, the research population would encompass all individuals who could potentially benefit from or be affected by the medication.
When Is Data Collection From a Population Preferred?
In certain scenarios where a comprehensive understanding of the entire group is required, it becomes necessary to collect data from a population. Here are a few situations when one prefers to collect data from a population:
1. Small or Accessible Population
When the research population is small or easily accessible, it may be feasible to collect data from the entire population. This is often the case in studies conducted within specific organizations, small communities, or well-defined groups where the population size is manageable.
2. Census or Complete Enumeration
In some cases, such as government surveys or official statistics, a census or complete enumeration of the population is necessary. This approach aims to gather data from every individual or entity within the population. This is typically done to ensure accurate representation and eliminate sampling errors.
3. Unique or Critical Characteristics
If the research focuses on a specific characteristic or trait that is rare and critical to the study, collecting data from the entire population may be necessary. This could be the case in studies related to rare diseases, endangered species, or specific genetic markers.
4. Legal or Regulatory Requirements
Certain legal or regulatory frameworks may require data collection from the entire population. For instance, government agencies might need comprehensive data on income levels, demographic characteristics, or healthcare utilization for policy-making or resource allocation purposes.
5. Precision or Accuracy Requirements
In situations where a high level of precision or accuracy is necessary, researchers may opt for population-level data collection. By doing so, they mitigate the potential for sampling error and obtain more reliable estimates of population parameters.
What Is a Sample?
A sample is a subset of the research population that is carefully selected to represent its characteristics. Researchers study this smaller, manageable group to draw inferences that they can generalize to the larger population. The selection of the sample must be conducted in a manner that ensures it accurately reflects the diversity and pertinent attributes of the research population. By studying a sample, researchers can gather data more efficiently and cost-effectively compared to studying the entire population. The findings from the sample are then extrapolated to make conclusions about the larger research population.
What Is Sampling and Why Is It Important?
Sampling refers to the process of selecting a sample from a larger group or population of interest in order to gather data and make inferences. The goal of sampling is to obtain a sample that is representative of the population, meaning that the sample accurately reflects the key attributes, variations, and proportions present in the population. By studying the sample, researchers can draw conclusions or make predictions about the larger population with a certain level of confidence.
Collecting data from a sample, rather than the entire population, offers several advantages and is often necessary due to practical constraints. Here are some reasons to collect data from a sample:
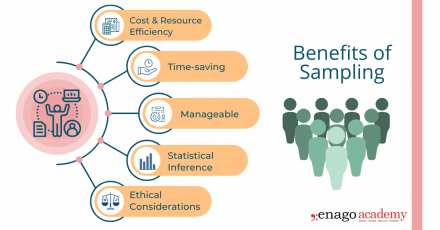
1. Cost and Resource Efficiency
Collecting data from an entire population can be expensive and time-consuming. Sampling allows researchers to gather information from a smaller subset of the population, reducing costs and resource requirements. It is often more practical and feasible to collect data from a sample, especially when the population size is large or geographically dispersed.
2. Time Constraints
Conducting research with a sample allows for quicker data collection and analysis compared to studying the entire population. It saves time by focusing efforts on a smaller group, enabling researchers to obtain results more efficiently. This is particularly beneficial in time-sensitive research projects or situations that necessitate prompt decision-making.
3. Manageable Data Collection
Working with a sample makes data collection more manageable . Researchers can concentrate their efforts on a smaller group, allowing for more detailed and thorough data collection methods. Furthermore, it is more convenient and reliable to store and conduct statistical analyses on smaller datasets. This also facilitates in-depth insights and a more comprehensive understanding of the research topic.
4. Statistical Inference
Collecting data from a well-selected and representative sample enables valid statistical inference. By using appropriate statistical techniques, researchers can generalize the findings from the sample to the larger population. This allows for meaningful inferences, predictions, and estimation of population parameters, thus providing insights beyond the specific individuals or elements in the sample.
5. Ethical Considerations
In certain cases, collecting data from an entire population may pose ethical challenges, such as invasion of privacy or burdening participants. Sampling helps protect the privacy and well-being of individuals by reducing the burden of data collection. It allows researchers to obtain valuable information while ensuring ethical standards are maintained .
Key Steps Involved in the Sampling Process
Sampling is a valuable tool in research; however, it is important to carefully consider the sampling method, sample size, and potential biases to ensure that the findings accurately represent the larger population and are valid for making conclusions and generalizations. While the specific steps may vary depending on the research context, here is a general outline of the sampling process:
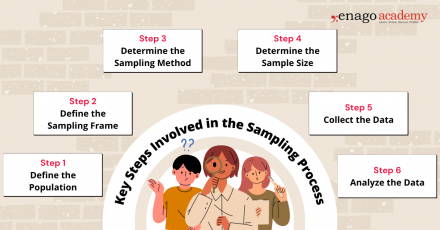
1. Define the Population
Clearly define the target population for your research study. The population should encompass the group of individuals, elements, or units that you want to draw conclusions about.
2. Define the Sampling Frame
Create a sampling frame, which is a list or representation of the individuals or elements in the target population. The sampling frame should be comprehensive and accurately reflect the population you want to study.
3. Determine the Sampling Method
Select an appropriate sampling method based on your research objectives, available resources, and the characteristics of the population. You can perform sampling by either utilizing probability-based or non-probability-based techniques. Common sampling methods include random sampling, stratified sampling, cluster sampling, and convenience sampling.
4. Determine Sample Size
Determine the desired sample size based on statistical considerations, such as the level of precision required, desired confidence level, and expected variability within the population. Larger sample sizes generally reduce sampling error but may be constrained by practical limitations.
5. Collect Data
Once the sample is selected using the appropriate technique, collect the necessary data according to the research design and data collection methods . Ensure that you use standardized and consistent data collection process that is also appropriate for your research objectives.
6. Analyze the Data
Perform the necessary statistical analyses on the collected data to derive meaningful insights. Use appropriate statistical techniques to make inferences, estimate population parameters, test hypotheses, or identify patterns and relationships within the data.
Population vs Sample — Differences and examples
While the population provides a comprehensive overview of the entire group under study, the sample, on the other hand, allows researchers to draw inferences and make generalizations about the population. Researchers should employ careful sampling techniques to ensure that the sample is representative and accurately reflects the characteristics and variability of the population.

Research Study: Investigating the prevalence of stress among high school students in a specific city and its impact on academic performance.
Population: All high school students in a particular city
Sampling Frame: The sampling frame would involve obtaining a comprehensive list of all high schools in the specific city. A random selection of schools would be made from this list to ensure representation from different areas and demographics of the city.
Sample: Randomly selected 500 high school students from different schools in the city
The sample represents a subset of the entire population of high school students in the city.
Research Study: Assessing the effectiveness of a new medication in managing symptoms and improving quality of life in patients with the specific medical condition.
Population: Patients diagnosed with a specific medical condition
Sampling Frame: The sampling frame for this study would involve accessing medical records or databases that include information on patients diagnosed with the specific medical condition. Researchers would select a convenient sample of patients who meet the inclusion criteria from the sampling frame.
Sample: Convenient sample of 100 patients from a local clinic who meet the inclusion criteria for the study
The sample consists of patients from the larger population of individuals diagnosed with the medical condition.
Research Study: Investigating community perceptions of safety and satisfaction with local amenities in the neighborhood.
Population: Residents of a specific neighborhood
Sampling Frame: The sampling frame for this study would involve obtaining a list of residential addresses within the specific neighborhood. Various sources such as census data, voter registration records, or community databases offer the means to obtain this information. From the sampling frame, researchers would randomly select a cluster sample of households to ensure representation from different areas within the neighborhood.
Sample: Cluster sample of 50 households randomly selected from different blocks within the neighborhood
The sample represents a subset of the entire population of residents living in the neighborhood.
To summarize, sampling allows for cost-effective data collection, easier statistical analysis, and increased practicality compared to studying the entire population. However, despite these advantages, sampling is subject to various challenges. These challenges include sampling bias, non-response bias, and the potential for sampling errors.
To minimize bias and enhance the validity of research findings , researchers should employ appropriate sampling techniques, clearly define the population, establish a comprehensive sampling frame, and monitor the sampling process for potential biases. Validating findings by comparing them to known population characteristics can also help evaluate the generalizability of the results. Properly understanding and implementing sampling techniques ensure that research findings are accurate, reliable, and representative of the larger population. By carefully considering the choice of population and sample, researchers can draw meaningful conclusions and, consequently, make valuable contributions to their respective fields of study.
Now, it’s your turn! Take a moment to think about a research question that interests you. Consider the population that would be relevant to your inquiry. Who would you include in your sample? How would you go about selecting them? Reflecting on these aspects will help you appreciate the intricacies involved in designing a research study. Let us know about it in the comment section below or reach out to us using #AskEnago and tag @EnagoAcademy on Twitter , Facebook , and Quora .

Thank you very much, this is helpful
Very impressive and helpful and also easy to understand….. Thanks to the Author and Publisher….
Rate this article Cancel Reply
Your email address will not be published.

Enago Academy's Most Popular Articles

- Publishing Research
- Trending Now
- Understanding Ethics
Understanding the Impact of Retractions on Research Integrity – A global study
As we reach the midway point of 2024, ‘Research Integrity’ remains one of the hot…

- Diversity and Inclusion
The Silent Struggle: Confronting gender bias in science funding
In the 1990s, Dr. Katalin Kariko’s pioneering mRNA research seemed destined for obscurity, doomed by…

- Reporting Research
Choosing the Right Analytical Approach: Thematic analysis vs. content analysis for data interpretation
In research, choosing the right approach to understand data is crucial for deriving meaningful insights.…

Addressing Barriers in Academia: Navigating unconscious biases in the Ph.D. journey
In the journey of academia, a Ph.D. marks a transitional phase, like that of a…

Comparing Cross Sectional and Longitudinal Studies: 5 steps for choosing the right approach
The process of choosing the right research design can put ourselves at the crossroads of…
Choosing the Right Analytical Approach: Thematic analysis vs. content analysis for…
Comparing Cross Sectional and Longitudinal Studies: 5 steps for choosing the right…

Sign-up to read more
Subscribe for free to get unrestricted access to all our resources on research writing and academic publishing including:
- 2000+ blog articles
- 50+ Webinars
- 10+ Expert podcasts
- 50+ Infographics
- 10+ Checklists
- Research Guides
We hate spam too. We promise to protect your privacy and never spam you.
- Industry News
- AI in Academia
- Promoting Research
- Career Corner
- Infographics
- Expert Video Library
- Other Resources
- Enago Learn
- Upcoming & On-Demand Webinars
- Open Access Week 2024
- Peer Review Week 2024
- Conference Videos
- Enago Report
- Journal Finder
- Enago Plagiarism & AI Grammar Check
- Editing Services
- Publication Support Services
- Research Impact
- Translation Services
- Publication solutions
- AI-Based Solutions
- Thought Leadership
- Call for Articles
- Call for Speakers
- Author Training
- Edit Profile
I am looking for Editing/ Proofreading services for my manuscript Tentative date of next journal submission:

What factors would influence the future of open access (OA) publishing?
- Social Science
CONCEPT OF POPULATION AND SAMPLE
- Conference: How to Write a Research Paper?
- At: Indore, M. P., India

- Gujarat University
Discover the world's research
- 25+ million members
- 160+ million publication pages
- 2.3+ billion citations
- Int J Sustain Dev Plann

- Abdul Walusansa
- Henry Natukwatsa

- Donah Asiimire
- Siti Yuliandi Ahmad
- Nur Qasdina Asyura Pg Idris
- Susi Banjarnahor
- Sri Y K Hardini

- Oyewale Kayode

- Corresponding Author
- Silvi Nur Hidayati
- Edi Pujo Basuki
- Novi Rahmania Aquariza

- MUSONI Wilson

- BRIT J EDUC TECHNOL
- Barry MacDonald

- Satishprakash Shukla
- Recruit researchers
- Join for free
- Login Email Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google Welcome back! Please log in. Email · Hint Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google No account? Sign up
Stack Exchange Network
Stack Exchange network consists of 183 Q&A communities including Stack Overflow , the largest, most trusted online community for developers to learn, share their knowledge, and build their careers.
Q&A for work
Connect and share knowledge within a single location that is structured and easy to search.
What is the definition of "source population"?
What is the definition of source population?
Suppose we screen $100,000$ people and then include $50,000$ people in three studies $A$, $B$ and $C$. For study $A$, is the source population the $50,000$ people or the $100,000$ people screened?
- terminology
- epidemiology
4 Answers 4
The source population in an epidemiological context should be the group that you would like to make inferences about, based on what you see in your sample.
The source population would be the one that the 100,000 people were drawn from - not necessarily only those 100,000 people. You say that these people were screened which I take to mean they were assessed in some way to determine eligibility to be a part of your sample of 50,000 people. There are then two possibilities that I can see:
(1) these 100,000 people represent the entirety of the population about which you want to make inferences, in which case the 100,000 people are the source population for all three studies and the subset of the 50,000 people selected to be in each study is the study sample for that study.
(2) these 100,000 people are a subset of the population about which you want to make inferences, and were selected in some way for screening. In this second case, the 100,000 people are not the source population - the source population is the population from which the 100,000 people were originally selected. This is true for all three studies. The 100,000 people can be considered a sample used for recruitment, and the subset of the 50,000 people used in each study is the specific study sample for that study.
The source population in your example is somewhat ambiguous - though a source population for any given study is often somewhat hard to define.
Generally speaking, the source population is the population from which your study subjects are drawn. In your example, that would be the 100,000 screened individuals under a specific assumption . Namely, that the screened population is an entire population.
For example, if your study screened 100,000 individuals in the U.S. Navy chosen at random, your source population is not the 100,000, but "Active duty members of the U.S. Navy". The smaller studies are just sub-sets of that 100,000 person group, but that's not the population you drew the study samples from.
I find the best way to think about the source population is to ask "Who could have been in my study?" Is there something about those 100,000 that means they're the only people who could possibly have enrolled, or is there a greater population out there that the 100,000 were themselves drawn from?
Rothman certainly implies that "source population" is just "population", in which case the source population would, I think, be the population from which the 100,000 people came. The 50,000 in each study is the sample.
- 1 $\begingroup$ The three studies have $50,000$ people in total. It wouldn't make sense for each study to have $50,000$ people. In this case, the $100,000$ people screened would still be the source population? $\endgroup$ – NebulousReveal Commented May 6, 2013 at 0:54
- $\begingroup$ The question is about adding them. If the studies do not interact, if for example they looked at baldness in females, dentition in youth, and some protein in the skin of people within a particular weight range - then a person could legitimately be in all of these without confounding. If each person was paid $1 for their participation then in terms of headcount payout they could be added to comprise 150k people as participants. That would not be illegitimate. If you claimed that in the combination of the studies 150k unique human beings were measured then that is false. $\endgroup$ – EngrStudent Commented Jun 5, 2013 at 21:23
Your Answer
Sign up or log in, post as a guest.
Required, but never shown
By clicking “Post Your Answer”, you agree to our terms of service and acknowledge you have read our privacy policy .
Not the answer you're looking for? Browse other questions tagged terminology epidemiology or ask your own question .
- Featured on Meta
- Upcoming initiatives on Stack Overflow and across the Stack Exchange network...
- Preventing unauthorized automated access to the network
Hot Network Questions
- How do we distinguish between "not filled in" and "unknown" in our data store?
- Could there be a legitimate reason for a SSH server to allow null authentication, to anyone?
- Why aren't activation functions variable as well instead of being fixed?
- Outlet randomly losing power
- Will this radio receiver work?
- What separates numbers from other mathematical objects and what justifies e.g. the quaternions to be called a number system?
- Windows SMB and NIC RSS
- 50s B&W sci-fi movie about an alien(s) that was eventually killed by cars' headlights
- Can we choose to believe our beliefs, for example, can we simply choose to believe in God?
- "Riiiight," he said. What synonym of said can be used here?
- Roll a die in 3D
- Are apples 25% air?
- Is this baseboard installation a good job?
- Is it possible to build a Full-Spectrum White Laser?
- Is the Hilbert Mumford Criterion true over the reals?
- What was Adam Smith's position on the American Revolution?
- Difference between "play your cards right" and "on the right track"
- I have two different statements for the t test and the single tail test
- What are alternative methods of combat if explosions like in guns are too dangerous to use because of explosive gases?
- Horror film from the 60's that ends with the protagonist kissing a woman, who becomes a rotten corpse
- What expressions (verbs) are used for the actions of adding ingredients (solid, fluid, powdery) into a container, specifically while cooking?
- What part of Homer is Pliny the Elder referring to in Natural History? (On the Use of Paper)
- Why/how am I over counting here?
- Can I become a software programmer with an Information Sciences degree?
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- Population vs Sample | Definitions, Differences & Examples
Population vs Sample | Definitions, Differences & Examples
Published on 3 May 2022 by Pritha Bhandari . Revised on 5 December 2022.

A population is the entire group that you want to draw conclusions about.
A sample is the specific group that you will collect data from. The size of the sample is always less than the total size of the population.
In research, a population doesn’t always refer to people. It can mean a group containing elements of anything you want to study, such as objects, events, organisations, countries, species, or organisms.
| Population | Sample |
|---|---|
| Advertisements for IT jobs in the UK | The top 50 search results for advertisements for IT jobs in the UK on 1 May 2020 |
| Songs from the Eurovision Song Contest | Winning songs from the Eurovision Song Contest that were performed in English |
| Undergraduate students in the UK | 300 undergraduate students from three UK universities who volunteer for your psychology research study |
| All countries of the world | Countries with published data available on birth rates and GDP since 2000 |
Table of contents
Collecting data from a population, collecting data from a sample, population parameter vs sample statistic, practice questions: populations vs samples, frequently asked questions about samples and populations.
Populations are used when your research question requires, or when you have access to, data from every member of the population.
Usually, it is only straightforward to collect data from a whole population when it is small, accessible and cooperative.
For larger and more dispersed populations, it is often difficult or impossible to collect data from every individual. For example, every 10 years, the federal US government aims to count every person living in the country using the US Census. This data is used to distribute funding across the nation.
However, historically, marginalised and low-income groups have been difficult to contact, locate, and encourage participation from. Because of non-responses, the population count is incomplete and biased towards some groups, which results in disproportionate funding across the country.
In cases like this, sampling can be used to make more precise inferences about the population.
Prevent plagiarism, run a free check.
When your population is large in size, geographically dispersed, or difficult to contact, it’s necessary to use a sample. With statistical analysis , you can use sample data to make estimates or test hypotheses about population data.
Ideally, a sample should be randomly selected and representative of the population. Using probability sampling methods (such as simple random sampling or stratified sampling ) reduces the risk of sampling bias and enhances both internal and external validity .
For practical reasons, researchers often use non-probability sampling methods . Non-probability samples are chosen for specific criteria; they may be more convenient or cheaper to access. Because of non-random selection methods, any statistical inferences about the broader population will be weaker than with a probability sample.
Reasons for sampling
- Necessity : Sometimes it’s simply not possible to study the whole population due to its size or inaccessibility.
- Practicality : It’s easier and more efficient to collect data from a sample.
- Cost-effectiveness : There are fewer participant, laboratory, equipment, and researcher costs involved.
- Manageability : Storing and running statistical analyses on smaller datasets is easier and reliable.
When you collect data from a population or a sample, there are various measurements and numbers you can calculate from the data. A parameter is a measure that describes the whole population. A statistic is a measure that describes the sample.
You can use estimation or hypothesis testing to estimate how likely it is that a sample statistic differs from the population parameter.
Sampling error
A sampling error is the difference between a population parameter and a sample statistic. In your study, the sampling error is the difference between the mean political attitude rating of your sample and the true mean political attitude rating of all undergraduate students in the Netherlands.
Sampling errors happen even when you use a randomly selected sample. This is because random samples are not identical to the population in terms of numerical measures like means and standard deviations .
Because the aim of scientific research is to generalise findings from the sample to the population, you want the sampling error to be low. You can reduce sampling error by increasing the sample size.
Samples are used to make inferences about populations . Samples are easier to collect data from because they are practical, cost-effective, convenient, and manageable.
Populations are used when a research question requires data from every member of the population. This is usually only feasible when the population is small and easily accessible.
A statistic refers to measures about the sample , while a parameter refers to measures about the population .
A sampling error is the difference between a population parameter and a sample statistic .
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bhandari, P. (2022, December 05). Population vs Sample | Definitions, Differences & Examples. Scribbr. Retrieved 15 October 2024, from https://www.scribbr.co.uk/research-methods/population-versus-sample/
Is this article helpful?

Pritha Bhandari
Other students also liked, sampling methods | types, techniques, & examples, a quick guide to experimental design | 5 steps & examples, what is quantitative research | definition & methods.
- Foundations
- Write Paper
Search form
- Experiments
- Anthropology
- Self-Esteem
- Social Anxiety
Research Population
All research questions address issues that are of great relevance to important groups of individuals known as a research population.
This article is a part of the guide:
- Non-Probability Sampling
- Convenience Sampling
- Random Sampling
- Stratified Sampling
- Systematic Sampling
Browse Full Outline
- 1 What is Sampling?
- 2.1 Sample Group
- 2.2 Research Population
- 2.3 Sample Size
- 2.4 Randomization
- 3.1 Statistical Sampling
- 3.2 Sampling Distribution
- 3.3.1 Random Sampling Error
- 4.1 Random Sampling
- 4.2 Stratified Sampling
- 4.3 Systematic Sampling
- 4.4 Cluster Sampling
- 4.5 Disproportional Sampling
- 5.1 Convenience Sampling
- 5.2 Sequential Sampling
- 5.3 Quota Sampling
- 5.4 Judgmental Sampling
- 5.5 Snowball Sampling
A research population is generally a large collection of individuals or objects that is the main focus of a scientific query. It is for the benefit of the population that researches are done. However, due to the large sizes of populations, researchers often cannot test every individual in the population because it is too expensive and time-consuming. This is the reason why researchers rely on sampling techniques .
A research population is also known as a well-defined collection of individuals or objects known to have similar characteristics. All individuals or objects within a certain population usually have a common, binding characteristic or trait.
Usually, the description of the population and the common binding characteristic of its members are the same. "Government officials" is a well-defined group of individuals which can be considered as a population and all the members of this population are indeed officials of the government.

Relationship of Sample and Population in Research
A sample is simply a subset of the population. The concept of sample arises from the inability of the researchers to test all the individuals in a given population. The sample must be representative of the population from which it was drawn and it must have good size to warrant statistical analysis.
The main function of the sample is to allow the researchers to conduct the study to individuals from the population so that the results of their study can be used to derive conclusions that will apply to the entire population. It is much like a give-and-take process. The population “gives” the sample, and then it “takes” conclusions from the results obtained from the sample.

Two Types of Population in Research
Target population.
Target population refers to the ENTIRE group of individuals or objects to which researchers are interested in generalizing the conclusions. The target population usually has varying characteristics and it is also known as the theoretical population.
Accessible Population
The accessible population is the population in research to which the researchers can apply their conclusions. This population is a subset of the target population and is also known as the study population. It is from the accessible population that researchers draw their samples.
- Psychology 101
- Flags and Countries
- Capitals and Countries
Explorable.com (Nov 15, 2009). Research Population. Retrieved Oct 17, 2024 from Explorable.com: https://explorable.com/research-population
You Are Allowed To Copy The Text
The text in this article is licensed under the Creative Commons-License Attribution 4.0 International (CC BY 4.0) .
This means you're free to copy, share and adapt any parts (or all) of the text in the article, as long as you give appropriate credit and provide a link/reference to this page.
That is it. You don't need our permission to copy the article; just include a link/reference back to this page. You can use it freely (with some kind of link), and we're also okay with people reprinting in publications like books, blogs, newsletters, course-material, papers, wikipedia and presentations (with clear attribution).
Want to stay up to date? Follow us!
Save this course for later.
Don't have time for it all now? No problem, save it as a course and come back to it later.
Footer bottom
- Privacy Policy

- Subscribe to our RSS Feed
- Like us on Facebook
- Follow us on Twitter
Study Population
Cite this chapter.

- Lawrence M. Friedman 6 ,
- Curt D. Furberg 7 ,
- David L. DeMets 8 ,
- David M. Reboussin 9 &
- Christopher B. Granger 10
115k Accesses
Defining the study population in the protocol is an integral part of posing the primary question. Additionally, in claiming an intervention is or is not effective it is essential to describe the type of participants on which the intervention was tested. Thus, the description requires two elements: specification of criteria for eligibility and description of who was actually enrolled. This chapter focuses on how to define the study population. In addition, it considers two questions. First, what impact does selection of eligibility criteria have on participant recruitment, or, more generally, study feasibility? Second, to what extent will the results of the trial be generalizable to a broader population? This issue is also discussed in Chap. 10 .
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
- Durable hardcover edition
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Similar content being viewed by others

The Recruitment, Sampling, and Enrollment Plan

Defining the Study Cohort: Inclusion and Exclusion Criteria

Subject Selection
Rothwell PM. External validity of randomized controlled trials: “To whom do the results of this trial apply?” Lancet 2005;365:82–93.
Article Google Scholar
CONSORT. http://www.consort-statement.org
Van Spall HGC, Toren A, Kiss A, Fowler RA. Eligibility criteria of randomized controlled trials published in high-impact general medical journals: a systematic sampling review. JAMA 2007;297:1233–1240.
Douglas PS. Gender, cardiology, and optimal medical care. Circulation 1986;74:917–919.
Bennett JC, for the Board on Health Sciences Policy of the Institute of Medicine. Inclusion of women in clinical trials – policies for population subgroups. N Engl J Med 1993;329:288–292.
Freedman LS, Simon R, Foulkes MA, et al. Inclusion of women and minorities in clinical trials and the NIH Revitalization Act of 1993 – the perspective of NIH clinical trialists. Control Clin Trials 1995;16:277–285.
Lee PY, Alexander KP, Hammill BG, et al. Representation of elderly persons and women in published randomized trials of acute coronary syndromes. JAMA 2001;286:708–713.
Google Scholar
NIH Policy and Guidelines on the Inclusion of Women and Minorities as Subjects in Clinical Research – Amended, October, 2001. http://grants.nih.gov/grants/funding/women_min/guidelines_amended_10_2001.htm
Diabetic Retinopathy Study Research Group: Preliminary report on effects of photocoagulation therapy. Am J Ophthalmol 1976;81:383–396.
Diabetic Retinopathy Study Research Group. Photocoagulation treatment of proliferative diabetic retinopathy: the second report of diabetic retinopathy study findings. Ophthalmol 1978;85:82–106.
Wooster R, Neuhausen SL, Mangion J, et al. Localization of a breast cancer susceptibility gene, BRCA2, to chromosome 13q12-13. Science 1994;265:2088–2090.
Patel MR, Mahaffey KW, Garg J, et al. for ROCKET AF investigators. Rivaroxaban versus warfarin in nonvalvular atrial fibrillation. N Engl J Med 2011;365:883–891.
Veterans Administration Cooperative Study Group on Antihypertensive Agents. Effects of treatment on morbidity in hypertension: results in patients with diastolic blood pressures averaging 115 through 129 mm Hg. JAMA 1967;202:1028–1034.
Veterans Administration Cooperative Study Group on Antihypertensive Agents. Effects of treatment on morbidity in hypertension: II. Results in patients with diastolic blood pressure averaging 90 through 114 mm Hg. JAMA 1970;213:1143–1152.
Hypertension Detection and Follow-up Program Cooperative Group. Five-year findings of the Hypertension Detection and Follow-up Program. 1. Reduction in mortality of persons with high blood pressure, including mild hypertension. JAMA 1979;242:2562–2571.
The CONSENSUS Trial Study Group. Effects of enalapril on mortality in severe heart failure. N Engl J Med 1987;316:1429–1435.
The SOLVD Investigators. Effect of enalapril on survival in patients with reduced left ventricular ejection fractions and congestive heart failure. N Engl J Med 1991;325:293–302.
The SOLVD Investigators. Effect of enalapril on mortality and the development of heart failure in asymptomatic patients with reduced left ventricular ejection fractions. N Engl J Med 1992;327:685–691.
Vollmer T. The natural history of relapses in multiple sclerosis. J Neurol Sci 2007;256:S5-S13.
Sondik EJ, Brown BW, Jr., Silvers A. High risk subjects and the cost of large field trials. J Chronic Dis 1974; 27:177–187.
Ridker PM, Danielson E, Fonseca FAH, et al. Rosuvastatin to prevent vascular events in men and women with elevated C-reactive protein. N Engl J Med 2008;359:2195–2207.
http://www.fda.gov/downloads/drugs/guidancecomplianceregulatoryinformation/guidances/ucm332181.pdf .
Darrow JJ, Avorn J, Kesselheim AS. New FDA breakthrough-drug category—implications for patients. N Engl J Med 2014;370:1252–1258.
McMurray JJV, Packer M, Desai AS, et al. Angiotensin-neprilysin inhibition versus enalapril in heart failure. N Engl J Med 2014;371:993–1004.
Tunis SR, Stryer DB, Clancy CM. Practical clinical trials: increasing the value of clinical research for decision making in clinical and health policy. JAMA. 2003;290:1624–1632.
Thorpe KE, Swarenstein M, Oxman AD, et al. A pragmatic-explanatory continuum indicator summary (PRECIS): a tool to help trial designers. J Clin Epidemiol 2009;62:464–475.
Ridker PM and PREVENT Investigators. Long-term, low does warfarin among venous thrombosis patients with and without factor V Leiden mutation: rationale and design for the Prevention of Recurrent Venous Thromboembolism (PREVENT) trial. Vasc Med 1998;3:67–73.
Mooney MM, Welch J, Abrams JS. Clinical trial design and master protocols in NCI clinical treatment trials. [abstract]. Clin Cancer Res 2014;20(2Suppl):Abstract IA08.
Hakonarson H, Thorvaldsson S, Helgadottir A, et al. Effects of a 5-lipoxygenase-activating protein inhibitor on biomarkers associated with risk of myocardial infarction: a randomized trial. JAMA 2005;293:2245–2256.
The U.S. Food and Drug Administration. Drugs. Table of pharmacogenomics biomarkers in labeling. www.fda.gov/drugs/scienceresearch/researchareas/pharmacogenetics/ucm083378.htm .
Mrazek DA. Psychiatric pharmacogenomics . New York: Oxford University Press, 2010.
Book Google Scholar
Landrum MJ, Lee JM, Riley GR, et al. ClinVar: public archive of relationships among sequence variation and human phenotype. Nucleic Acids Res 2014;42 (Database issue):D980-5.
Mailman MD, Feolo M, Jin Y, et al. The NCBI dbGaP database of genotypes and phenotypes. Nat Genet 2007;39:1181–1186.
Wilhelmsen L, Ljungberg S, Wedel H, Werko L. A comparison between participants and non-participants in a primary preventive trial. J Chronic Dis. 1976;29:331–339.
Smith P, Arnesen H. Mortality in non-consenters in a post-myocardial infarction trial. J Intern Med 1990; 228:253–256.
Antithrombotic Trialists’ Collaboration. Collaborative meta-analysis of randomized clinical trials of antiplatelet therapy for prevention of death, myocardial infarction, and stroke in high risk patients. BMJ 2002;324:71–86; correction BMJ 2002;324:141.
Steering Committee of the Physicians’ Health Study Research Group. Final report on the aspirin component of the ongoing Physicians’ Health Study. N Engl J Med 1989;321:129–135.
Peto R, Gray R, Collins R, et al. Randomized trial of prophylactic daily aspirin in British male doctors. Br Med J 1988;296:313–316.
Ridker PM, Cook NR, Lee I-M, et al. A randomized trial of low-dose aspirin in the primary prevention of cardiovascular disease in women. N Engl J Med 2005;352:1293–1304.
Ikeda Y, Shimada K, Teramoto T, et al. Low-dose aspirin for primary prevention of cardiovascular events in Japanese patients 60 years or older with atherosclerotic risk factors. A randomized clinical trial. JAMA. Published online November 17, 2014. doi: 10.1001/jama.2014.15690 .
Berger JS, Roncaglioni MC, Avanzini F, et al. Aspirin for the primary prevention of cardiovascular events in women and men: a sex-specific meta-analysis of randomized controlled trials. JAMA 2006;295:306–313; correction JAMA 2006;295:2002.
Pedersen TR. The Norwegian Multicenter Study of timolol after myocardial infarction. Circulation 1983;67 (suppl 1):I-49-1-53.
CASS Principal Investigators and Their Associates. Coronary Artery Surgery Study (CASS): a randomized trial of coronary artery bypass surgery. Comparability of entry characteristics and survival in randomized patients and nonrandomized patients meeting randomization criteria. J Am Coll Cardiol 1984;3:114–128.
Kaariainen I, Sipponen P, Siurala M. What fraction of hospital ulcer patients is eligible for prospective drug trials? Scand J Gastroenterol 1991;186:73–76.
Benedict GW. LRC Coronary Prevention Trial: Baltimore. Clin Pharmacol Ther 1979;25:685–687.
Pitt B, Pfeffer MA, Assmann SF, et al. TOPCAT Investigators. Spironolactone for heart failure with preserved ejection fraction. N Engl J Med 2014;370:1383–1392.
Download references
Author information
Authors and affiliations.
North Bethesda, MD, USA
Lawrence M. Friedman
Division of Public Health Sciences, Wake Forest School of Medicine, Winston-Salem, NC, USA
Curt D. Furberg
Department Biostatistics and Medical Informatics, University of Wisconsin, Madison, WI, USA
David L. DeMets
Department of Biostatistics, Wake Forest School of Medicine, Winston-Salem, NC, USA
David M. Reboussin
Department of Medicine, Duke University, Durham, NC, USA
Christopher B. Granger
You can also search for this author in PubMed Google Scholar
Rights and permissions
Reprints and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this chapter
Friedman, L.M., Furberg, C.D., DeMets, D.L., Reboussin, D.M., Granger, C.B. (2015). Study Population. In: Fundamentals of Clinical Trials. Springer, Cham. https://doi.org/10.1007/978-3-319-18539-2_4
Download citation
DOI : https://doi.org/10.1007/978-3-319-18539-2_4
Publisher Name : Springer, Cham
Print ISBN : 978-3-319-18538-5
Online ISBN : 978-3-319-18539-2
eBook Packages : Mathematics and Statistics Mathematics and Statistics (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- What Is a Research Design | Types, Guide & Examples
What Is a Research Design | Types, Guide & Examples
Published on June 7, 2021 by Shona McCombes . Revised on September 5, 2024 by Pritha Bhandari.
A research design is a strategy for answering your research question using empirical data. Creating a research design means making decisions about:
- Your overall research objectives and approach
- Whether you’ll rely on primary research or secondary research
- Your sampling methods or criteria for selecting subjects
- Your data collection methods
- The procedures you’ll follow to collect data
- Your data analysis methods
A well-planned research design helps ensure that your methods match your research objectives and that you use the right kind of analysis for your data.
You might have to write up a research design as a standalone assignment, or it might be part of a larger research proposal or other project. In either case, you should carefully consider which methods are most appropriate and feasible for answering your question.
Table of contents
Step 1: consider your aims and approach, step 2: choose a type of research design, step 3: identify your population and sampling method, step 4: choose your data collection methods, step 5: plan your data collection procedures, step 6: decide on your data analysis strategies, other interesting articles, frequently asked questions about research design.
- Introduction
Before you can start designing your research, you should already have a clear idea of the research question you want to investigate.
There are many different ways you could go about answering this question. Your research design choices should be driven by your aims and priorities—start by thinking carefully about what you want to achieve.
The first choice you need to make is whether you’ll take a qualitative or quantitative approach.
| Qualitative approach | Quantitative approach |
|---|---|
| and describe frequencies, averages, and correlations about relationships between variables |
Qualitative research designs tend to be more flexible and inductive , allowing you to adjust your approach based on what you find throughout the research process.
Quantitative research designs tend to be more fixed and deductive , with variables and hypotheses clearly defined in advance of data collection.
It’s also possible to use a mixed-methods design that integrates aspects of both approaches. By combining qualitative and quantitative insights, you can gain a more complete picture of the problem you’re studying and strengthen the credibility of your conclusions.
Practical and ethical considerations when designing research
As well as scientific considerations, you need to think practically when designing your research. If your research involves people or animals, you also need to consider research ethics .
- How much time do you have to collect data and write up the research?
- Will you be able to gain access to the data you need (e.g., by travelling to a specific location or contacting specific people)?
- Do you have the necessary research skills (e.g., statistical analysis or interview techniques)?
- Will you need ethical approval ?
At each stage of the research design process, make sure that your choices are practically feasible.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

Within both qualitative and quantitative approaches, there are several types of research design to choose from. Each type provides a framework for the overall shape of your research.
Types of quantitative research designs
Quantitative designs can be split into four main types.
- Experimental and quasi-experimental designs allow you to test cause-and-effect relationships
- Descriptive and correlational designs allow you to measure variables and describe relationships between them.
| Type of design | Purpose and characteristics |
|---|---|
| Experimental | relationships effect on a |
| Quasi-experimental | ) |
| Correlational | |
| Descriptive |
With descriptive and correlational designs, you can get a clear picture of characteristics, trends and relationships as they exist in the real world. However, you can’t draw conclusions about cause and effect (because correlation doesn’t imply causation ).
Experiments are the strongest way to test cause-and-effect relationships without the risk of other variables influencing the results. However, their controlled conditions may not always reflect how things work in the real world. They’re often also more difficult and expensive to implement.
Types of qualitative research designs
Qualitative designs are less strictly defined. This approach is about gaining a rich, detailed understanding of a specific context or phenomenon, and you can often be more creative and flexible in designing your research.
The table below shows some common types of qualitative design. They often have similar approaches in terms of data collection, but focus on different aspects when analyzing the data.
| Type of design | Purpose and characteristics |
|---|---|
| Grounded theory | |
| Phenomenology |
Your research design should clearly define who or what your research will focus on, and how you’ll go about choosing your participants or subjects.
In research, a population is the entire group that you want to draw conclusions about, while a sample is the smaller group of individuals you’ll actually collect data from.
Defining the population
A population can be made up of anything you want to study—plants, animals, organizations, texts, countries, etc. In the social sciences, it most often refers to a group of people.
For example, will you focus on people from a specific demographic, region or background? Are you interested in people with a certain job or medical condition, or users of a particular product?
The more precisely you define your population, the easier it will be to gather a representative sample.
- Sampling methods
Even with a narrowly defined population, it’s rarely possible to collect data from every individual. Instead, you’ll collect data from a sample.
To select a sample, there are two main approaches: probability sampling and non-probability sampling . The sampling method you use affects how confidently you can generalize your results to the population as a whole.
| Probability sampling | Non-probability sampling |
|---|---|
Probability sampling is the most statistically valid option, but it’s often difficult to achieve unless you’re dealing with a very small and accessible population.
For practical reasons, many studies use non-probability sampling, but it’s important to be aware of the limitations and carefully consider potential biases. You should always make an effort to gather a sample that’s as representative as possible of the population.
Case selection in qualitative research
In some types of qualitative designs, sampling may not be relevant.
For example, in an ethnography or a case study , your aim is to deeply understand a specific context, not to generalize to a population. Instead of sampling, you may simply aim to collect as much data as possible about the context you are studying.
In these types of design, you still have to carefully consider your choice of case or community. You should have a clear rationale for why this particular case is suitable for answering your research question .
For example, you might choose a case study that reveals an unusual or neglected aspect of your research problem, or you might choose several very similar or very different cases in order to compare them.
Data collection methods are ways of directly measuring variables and gathering information. They allow you to gain first-hand knowledge and original insights into your research problem.
You can choose just one data collection method, or use several methods in the same study.
Survey methods
Surveys allow you to collect data about opinions, behaviors, experiences, and characteristics by asking people directly. There are two main survey methods to choose from: questionnaires and interviews .
| Questionnaires | Interviews |
|---|---|
| ) |
Observation methods
Observational studies allow you to collect data unobtrusively, observing characteristics, behaviors or social interactions without relying on self-reporting.
Observations may be conducted in real time, taking notes as you observe, or you might make audiovisual recordings for later analysis. They can be qualitative or quantitative.
| Quantitative observation | |
|---|---|
Other methods of data collection
There are many other ways you might collect data depending on your field and topic.
| Field | Examples of data collection methods |
|---|---|
| Media & communication | Collecting a sample of texts (e.g., speeches, articles, or social media posts) for data on cultural norms and narratives |
| Psychology | Using technologies like neuroimaging, eye-tracking, or computer-based tasks to collect data on things like attention, emotional response, or reaction time |
| Education | Using tests or assignments to collect data on knowledge and skills |
| Physical sciences | Using scientific instruments to collect data on things like weight, blood pressure, or chemical composition |
If you’re not sure which methods will work best for your research design, try reading some papers in your field to see what kinds of data collection methods they used.
Secondary data
If you don’t have the time or resources to collect data from the population you’re interested in, you can also choose to use secondary data that other researchers already collected—for example, datasets from government surveys or previous studies on your topic.
With this raw data, you can do your own analysis to answer new research questions that weren’t addressed by the original study.
Using secondary data can expand the scope of your research, as you may be able to access much larger and more varied samples than you could collect yourself.
However, it also means you don’t have any control over which variables to measure or how to measure them, so the conclusions you can draw may be limited.
Prevent plagiarism. Run a free check.
As well as deciding on your methods, you need to plan exactly how you’ll use these methods to collect data that’s consistent, accurate, and unbiased.
Planning systematic procedures is especially important in quantitative research, where you need to precisely define your variables and ensure your measurements are high in reliability and validity.
Operationalization
Some variables, like height or age, are easily measured. But often you’ll be dealing with more abstract concepts, like satisfaction, anxiety, or competence. Operationalization means turning these fuzzy ideas into measurable indicators.
If you’re using observations , which events or actions will you count?
If you’re using surveys , which questions will you ask and what range of responses will be offered?
You may also choose to use or adapt existing materials designed to measure the concept you’re interested in—for example, questionnaires or inventories whose reliability and validity has already been established.
Reliability and validity
Reliability means your results can be consistently reproduced, while validity means that you’re actually measuring the concept you’re interested in.
| Reliability | Validity |
|---|---|
| ) ) |
For valid and reliable results, your measurement materials should be thoroughly researched and carefully designed. Plan your procedures to make sure you carry out the same steps in the same way for each participant.
If you’re developing a new questionnaire or other instrument to measure a specific concept, running a pilot study allows you to check its validity and reliability in advance.
Sampling procedures
As well as choosing an appropriate sampling method , you need a concrete plan for how you’ll actually contact and recruit your selected sample.
That means making decisions about things like:
- How many participants do you need for an adequate sample size?
- What inclusion and exclusion criteria will you use to identify eligible participants?
- How will you contact your sample—by mail, online, by phone, or in person?
If you’re using a probability sampling method , it’s important that everyone who is randomly selected actually participates in the study. How will you ensure a high response rate?
If you’re using a non-probability method , how will you avoid research bias and ensure a representative sample?
Data management
It’s also important to create a data management plan for organizing and storing your data.
Will you need to transcribe interviews or perform data entry for observations? You should anonymize and safeguard any sensitive data, and make sure it’s backed up regularly.
Keeping your data well-organized will save time when it comes to analyzing it. It can also help other researchers validate and add to your findings (high replicability ).
On its own, raw data can’t answer your research question. The last step of designing your research is planning how you’ll analyze the data.
Quantitative data analysis
In quantitative research, you’ll most likely use some form of statistical analysis . With statistics, you can summarize your sample data, make estimates, and test hypotheses.
Using descriptive statistics , you can summarize your sample data in terms of:
- The distribution of the data (e.g., the frequency of each score on a test)
- The central tendency of the data (e.g., the mean to describe the average score)
- The variability of the data (e.g., the standard deviation to describe how spread out the scores are)
The specific calculations you can do depend on the level of measurement of your variables.
Using inferential statistics , you can:
- Make estimates about the population based on your sample data.
- Test hypotheses about a relationship between variables.
Regression and correlation tests look for associations between two or more variables, while comparison tests (such as t tests and ANOVAs ) look for differences in the outcomes of different groups.
Your choice of statistical test depends on various aspects of your research design, including the types of variables you’re dealing with and the distribution of your data.
Qualitative data analysis
In qualitative research, your data will usually be very dense with information and ideas. Instead of summing it up in numbers, you’ll need to comb through the data in detail, interpret its meanings, identify patterns, and extract the parts that are most relevant to your research question.
Two of the most common approaches to doing this are thematic analysis and discourse analysis .
| Approach | Characteristics |
|---|---|
| Thematic analysis | |
| Discourse analysis |
There are many other ways of analyzing qualitative data depending on the aims of your research. To get a sense of potential approaches, try reading some qualitative research papers in your field.
If you want to know more about the research process , methodology , research bias , or statistics , make sure to check out some of our other articles with explanations and examples.
- Simple random sampling
- Stratified sampling
- Cluster sampling
- Likert scales
- Reproducibility
Statistics
- Null hypothesis
- Statistical power
- Probability distribution
- Effect size
- Poisson distribution
Research bias
- Optimism bias
- Cognitive bias
- Implicit bias
- Hawthorne effect
- Anchoring bias
- Explicit bias
A research design is a strategy for answering your research question . It defines your overall approach and determines how you will collect and analyze data.
A well-planned research design helps ensure that your methods match your research aims, that you collect high-quality data, and that you use the right kind of analysis to answer your questions, utilizing credible sources . This allows you to draw valid , trustworthy conclusions.
Quantitative research designs can be divided into two main categories:
- Correlational and descriptive designs are used to investigate characteristics, averages, trends, and associations between variables.
- Experimental and quasi-experimental designs are used to test causal relationships .
Qualitative research designs tend to be more flexible. Common types of qualitative design include case study , ethnography , and grounded theory designs.
The priorities of a research design can vary depending on the field, but you usually have to specify:
- Your research questions and/or hypotheses
- Your overall approach (e.g., qualitative or quantitative )
- The type of design you’re using (e.g., a survey , experiment , or case study )
- Your data collection methods (e.g., questionnaires , observations)
- Your data collection procedures (e.g., operationalization , timing and data management)
- Your data analysis methods (e.g., statistical tests or thematic analysis )
A sample is a subset of individuals from a larger population . Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
In statistics, sampling allows you to test a hypothesis about the characteristics of a population.
Operationalization means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioral avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalize the variables that you want to measure.
A research project is an academic, scientific, or professional undertaking to answer a research question . Research projects can take many forms, such as qualitative or quantitative , descriptive , longitudinal , experimental , or correlational . What kind of research approach you choose will depend on your topic.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
McCombes, S. (2024, September 05). What Is a Research Design | Types, Guide & Examples. Scribbr. Retrieved October 15, 2024, from https://www.scribbr.com/methodology/research-design/
Is this article helpful?

Shona McCombes
Other students also liked, guide to experimental design | overview, steps, & examples, how to write a research proposal | examples & templates, ethical considerations in research | types & examples, what is your plagiarism score.
An official website of the United States government
Official websites use .gov A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS A lock ( Lock Locked padlock icon ) or https:// means you've safely connected to the .gov website. Share sensitive information only on official, secure websites.
- Publications
- Account settings
- Advanced Search
- Journal List
Who and What Is a “Population”? Historical Debates, Current Controversies, and Implications for Understanding “Population Health” and Rectifying Health Inequities
Nancy krieger.
- Author information
- Article notes
- Copyright and License information
Address correspondence to: Nancy Krieger, Department of Society, Human Development and Health, Harvard School of Public Health, Kresge 717, 677 Huntington Avenue, Boston, MA 02115 (email: [email protected] ).
Issue date 2012 Dec.
The idea of “population” is core to the population sciences but is rarely defined except in statistical terms. Yet who and what defines and makes a population has everything to do with whether population means are meaningful or meaningless, with profound implications for work on population health and health inequities.
In this article, I review the current conventional definitions of, and historical debates over, the meaning(s) of “population,” trace back the contemporary emphasis on populations as statistical rather than substantive entities to Adolphe Quetelet's powerful astronomical metaphor, conceived in the 1830s, of l’homme moyen (the average man), and argue for an alternative definition of populations as relational beings. As informed by the ecosocial theory of disease distribution, I then analyze several case examples to explore the utility of critical population-informed thinking for research, knowledge, and policy involving population health and health inequities.
Four propositions emerge: (1) the meaningfulness of means depends on how meaningfully the populations are defined in relation to the inherent intrinsic and extrinsic dynamic generative relationships by which they are constituted; (2) structured chance drives population distributions of health and entails conceptualizing health and disease, including biomarkers, as embodied phenotype and health inequities as historically contingent; (3) persons included in population health research are study participants, and the casual equation of this term with “study population” should be avoided; and (4) the conventional cleavage of “internal validity” and “generalizability” is misleading, since a meaningful choice of study participants must be in relation to the range of exposures experienced (or not) in the real-world societies, that is, meaningful populations, of which they are a part.
Conclusions
To improve conceptual clarity, causal inference, and action to promote health equity, population sciences need to expand and deepen their theorizing about who and what makes populations and their means.
Keywords: epidemiology, health inequities, history, population health
Population sciences, whether focused on people or the plenitude of other species with which we inhabit this world, rely on a remarkable, almost alchemical, feat that nevertheless now passes as commonplace: creating causal and actionable knowledge via the transmutation of data from unique individuals into population distributions, dynamics, and rates. In the case of public health, a comparison of population data—especially rates and averages of traits—sets the basis for not only elucidating etiology but also identifying and addressing health, health care, and health policy inequities manifested in differential outcomes caused by social injustice ( Davis and Rowland 1983 ; Irwin et al. 2006 ; Krieger 2001 , 2011 ; Svensson 1990 ; Whitehead 1992 ; WHO 2008 , 2011 ).
But who are these “populations,” and why should their means be meaningful? Might some instead be meaningless, the equivalent of fool's gold or, worse, dangerously misleading?
Because “population” is such a fundamental term for so many sciences that analyze population data—for example, epidemiology, demography, sociology, ecology, and population biology and population genetics, not to mention statistics and biostatistics (see, e.g., Desrosières 1998 ; Gaziano 2010 ; Greenhalgh 1996 ; Hey 2011 ; Kunitz 2007 ; Mayr 1988 ; Pearce 1999 ; Porter 1986 ; Ramsden 2002 ; Stigler 1986 ; Weiss and Long 2009 )—presumably it would be reasonable to posit that the meaning of “population” is clear-cut and needs no further discussion.
As I document in this article, the surprise instead is that although the idea of “population” is core to the population sciences, it is rarely defined, especially in sciences dealing with people, except in abstract statistical terms. Granted, the “fuzziness” of concepts sometimes can be useful, especially when their empirical content is still being worked out, as illustrated by the well-documented contested history of the meanings of the “gene” as variously an abstract, functional, or physical entity, extending from before and still continuing well after the mid-twentieth-century discovery of DNA ( Burian and Zallen 2009 ; Falk 2000 ; Keller 2000 ; Morange 2001 ). Nevertheless, such fuzziness can also be a major problem, especially if the lack of clear definition or a conflation of meanings distorts causal analysis and accountability.
In this article, I accordingly call for expanding and deepening what I term “critical population-informed thinking.” Such thinking is needed to reckon with, among other things, claims of “population-based” evidence, principles for comparing results across “populations” (and their “subpopulations”), terminology regarding “study participants” (vs. “study population”), and assessing the validity (and not just the generalizability) of results. Addressing these issues requires clearly differentiating between (1) the dominant view that populations are (statistical) entities composed of component parts defined by innate attributes and (2) the alternative that I describe, in which populations are dynamic beings constituted by intrinsic relationships both among their members and with the other populations that together produce their existence and make meaningful casual inference possible.
To make my case, I review current conventional definitions of, and historical debates over, the meaning(s) of “population” and then offer case examples involving population health and health inequities. Informing my argument is the ecosocial theory of disease distribution and its focus on how people literally biologically embody their societal and ecological context, at multiple levels, across the life course and historical generations ( Krieger 1994 , 2001 , 2011 ), thereby producing population patterns of health, disease, and well-being.
Who and What Is a Population?
Conventional definitions.
Who and what determines who and what counts as a “population”? Table 1 lists conventional definitions culled from several contemporary scholarly reference texts. As quickly becomes apparent, the meaning of this term has expanded over time to embrace a variety of concepts. Tracing its etymology to the word's Latin roots, the Oxford English Dictionary ( OED 2010 ), for example, notes that “population” originally referred to the people living in (i.e., populating) a particular place, and this remains its primary meaning. Even so, as the OED 's definitions also make clear, “population” has come to acquire a technical meaning. In statistics, it refers to “a (real or hypothetical) totality of objects or individuals under consideration, of which the statistical attributes may be estimated by the study of a sample or samples drawn from it.” In genetics (or, really, biology more broadly), the OED defines “population” as “a group of animals, plants, or humans, within which breeding occurs.” Likewise, atoms, subatomic particles, stars, and other “celestial objects” are stated as sharing certain properties allowing them to be classed together in “populations” (even though the study of inanimate objects typically falls outside the purview of the “population sciences”).
Definitions of “Population” from Scholarly Reference Texts
| (OED 2010): |
| post-classical Latin , population, multitude (5th cent.), colonization, settlement (11th cent.), rural settlement (13th cent.), populousness (13th cent. in a British source) < , past participial stem of POPULATE . 2 + classical Latin -ION 1. |
| I. General uses. |
| 2. a. The extent to which a place is populated or inhabited; the collective inhabitants of a country, town, or other area; a body of inhabitants. |
| b. In extended use (chiefly applied to animals). |
| d. A group of people, esp. regarded as a class or subset within a larger group. Freq. with modifying word. |
| II. Technical uses. |
| 4. . A (real or hypothetical) totality of objects or individuals under consideration, of which the statistical attributes may be estimated by the study of a sample or samples drawn from it. |
| 5. . A group of animals, plants, or humans, within which breeding occurs. |
| 6. . The (number of) atoms or subatomic particles that occupy any particular energy state. |
| 7. . Any of several groups, originally two in number, into which stars and other celestial objects are categorized on the basis of where in the galaxy they were formed. Chiefly in n., n., n. at Compounds 2. |
| population biology . the branch of biology that deals with the patterns and causes of diversity within and among populations, esp. as regards their ecology, demography, epidemiology, etc. |
| population genetics . the branch of genetics that deals mathematically with the distribution of and change in gene frequencies in populations from one generation to another. |
| Oxford: ( , 651): |
| population (in ecology). 1. A group of individuals of the same species within a community. The nature of a population is determined by such factors as density, sex ratio, birth and death rates, emigration, and immigration. 2. The total number of individuals of a given species or other class of organisms in a defined area, e.g., the population of rodents in Britain. |
| Oxford: ( , 187): |
| POPULATION. 1. All the inhabitants of a given country or area considered together; the number of inhabitants of a given country or area. 2. In sampling, the whole collection of units (the “universe”) from which a sample may be drawn; not necessarily a population of persons—the units may be institutions, records, or events. The sample is intended to give results that are representative of the whole population; it may deviate from that goal owing to random and systematic errors. See also general population. |
| Oxford: ( , 504–5): population. In its most general sense, a population comprises the totality of the people living in a particular territory ( demography), but it has a more specific meaning in statistics. In statistical terms, a population refers to the aggregate of the individuals or units from which a sample is drawn, and to which the results of any analysis are to apply—in other words the aggregate of persons or objects under investigation. It is conventional to distinguish the target population (for which the results are required) from the survey population (those actually included in the sampling frame from which the sample is drawn). For practical reasons the two are rarely identical. Even the most complete sampling frames—electoral registers, lists of addresses, or (in the United States), lists of telephone numbers—exclude sizeable categories of the population (who fail to register to vote, are homeless, or do not own a telephone). Researchers may sometimes deliberately exclude members of the target population from the survey population. For example, it is standard practice to exclude the area north of the Caledonian Canal from the sampling frame for national sample surveys in Great Britain, on the grounds that the Northern Highlands are so thinly populated that interviews in this area would be unacceptably expensive to obtain. However, for most sociological purposes, this particular gap between the target and survey populations is not deemed to be significant—although, in a survey of ‘attitudes to public transportation in thinly populated areas,’ it would clearly be problematic. statistical inference. |
| : entry on “Human evolutionary genetics” ( , 6985): |
| Essential to the practice of human evolutionary genetics are definitions of the terms ‘population’ and ‘group.’ The less precisely defined term, ‘group,’ is used here to mean any collection of individuals. In a theoretical framework, the term ‘population’ is defined very precisely, as a set of individuals constituting a mating pool. All individuals of the appropriate sex in the population are considered to be equally available as potential mates. Groups of humans rarely, if ever, fit this definition of a population. The boundary between one population and another is obscure. In practice, therefore, human evolutionary geneticists delineate populations along linguistic, geographic, sociopolitical, and/or cultural boundaries. A population might include, for example, all speakers of a particular Bantu language, all inhabitants of a river valley in Italy, or all members of a caste group in India. |
| : entry on “Generalization: conceptions in the social sciences” ( , 6038): |
| … many social scientists use universe (and population) differently from construct …. In statistics, populations are ostensive; their elements are real and can be pointed to. But constructs are hypothetical and more obviously theory dependent. Moreover, the formal methods statisticians prefer when sampling elements from a population cannot be used with constructs, because the necessary enumeration and sampling of elements cannot be readily achieved with measures of abstract constructs. This is why Cook and Campbell (1979) used external validity to refer to people and settings and construct validity to refer to instances of more hypothetical causes and effects. However, the distinction is partly arbitrary. Constructs have constitutive elements theoretically specified as their components, and instances of any one construct vary in which components they incorporate. Moreover, human populations are not totally ostensive . Despite official definitions, there is still room to disagree about what being an Australian means: what about someone with an Australian passport who has always lived abroad, or the illegal immigrant who has always lived in Australia without a passport? |
Mirroring the OED 's definitions are those provided in diverse “population sciences” dictionaries and encyclopedias. Four such texts, whose definitions are echoed in key works in population health ( Evans, Barer, and Marmor 1994 ; Rose 1992 , 2008 ; Rothman, Greenland, and Lash 2008 ; Young 2005 ), are worth noting: A Dictionary of Epidemiology ( Porta 2008 ), A Dictionary of Sociology ( Scott and Marshall 2005 ), and the two entries from the International Encyclopedia of the Social & Behavioral Sciences that offer a definition of “population,” one focused on “human evolutionary genetics” ( Mountain 2001 ) and the other on “generalization: conceptions in the social sciences” ( Cook 2001 ). A fifth resource, the Encyclopedia of Life Sciences , interestingly does not include any articles specifically on defining “population.” However, of the 396 entries located with the search term “population” and sorted by “relevance,” the first 25 focus on populations principally in relation to genetics, reproduction, and natural selection ( Clarke et al. 2000 –2011).
Among these four texts, all germane to population sciences that study people, the first two briefly define “population” in relation to inhabitants of an area but notably remain mum on the myriad populations appearing in the public health literature not linked to geographic locale (e.g., the “elderly population,” the “white population,” or the “lesbian/gay/bisexual/transgender population”). Most of their text is instead devoted to the idea of “population” in relation to statistical sampling ( Porta 2008 ; Scott and Marshall 2005 ). By contrast, the third text invokes biology (with no mention of statistics) and defines a “population” to be a “mating pool” ( Mountain 2001 , 6985), albeit observing that “groups of humans rarely, if ever, meet this definition,” so that “in practice … human evolutionary geneticists delineate populations along linguistic, geographic, socio-political, and/or cultural boundaries. A population might include, for example, all speakers of a particular Bantu language, all inhabitants of a river valley in Italy, or all members of a caste group in India.”
The fourth text avers that in the social sciences, “population” has two meanings: as a theory-dependent hypothetical “construct” (whose basis is not defined) and as an empirically defined “universe” (used as a sampling frame) ( Cook 2001 ). A telling example illustrates that for people, geographical location, nationality, and ancestry need not neatly match, as in the case of an illegal immigrant or a legal citizen of one country legally residing in a different country ( table 1 ). Consequently, apart from specifying that entities comprising a population individually possess some attribute qualifying them to be a member of that population, none of the conventional definitions offers systematic criteria by which to decide, in theoretical or practical terms, who and what is a population, let alone whether and, if so, why their mean value or rate (or any statistical parameter) might have any substantive meaning.
Meet the “Average Man”: Quetelet's 1830s Astronomical Metaphor Amalgamating “Population” and “Statistics”
The overarching emphasis on “populations” as technical statistical entities and the limited discussion as to what defines them, especially for the human populations, is at once remarkable and unsurprising. It is remarkable because “population” stands at the core, conceptually and empirically, of any and all population sciences. It is unsurprising, given the history and politics of how, in the case of people, “population” and “sample” first were joined ( Krieger 2011 ).
In brief, and as recounted by numerous historians of statistics ( Daston 1987 ; Desrosières 1998 ; Hacking 1975 , 1990 ; Porter 1981 , 1986 , 1995 , 2002 , 2003 ; Stigler 1986 , 2002 ; Yeo 2003 ), during the early 1800s the application of quantitative methods and laws of probability to the study of people in Europe took off, a feat that required reckoning with such profound issues as free will, God's will, and human fate. To express the mind shift involved, a particularly powerful metaphor took root: that of the “l’homme moyen” (the average man), which, in the convention of the day, included women ( figure 1 ). First used in 1831 in an address given by Adolphe Quetelet (1796–1874), the Belgian astronomer-turned-statistician-turned-sociologist-turned-nosologist ( Hankins 1968 ; Stigler 2002 ), the metaphor gained prominence following the publication in 1835 of Quetelet's enormously influential opus, Sur l’homme et le development de ses facultés, ou essai de physique sociale ( Quetelet 1835 ). Melding the ideas of essential types, external influences, and random errors, the image of the “average man” solidified a view of populations, particularly human populations, as innately defined by their intrinsic qualities. Revealing these innate qualities, according to Quetelet, was a population's on-average traits, whether pertaining to height and weight, birth and death rates, intellectual faculties, moral properties, and even propensity to commit crime ( Quetelet 1835 , 1844 ).

What is the meaning of means and errors?—Adolphe Quetelet (1796–1874) and the astronomical metaphor animating his 1830s “I'homme moyen” (“the average man”).
Source: Illustration of normal curve from Quetelet 1844 .
The metaphor animating Quetelet's “average man” was inspired by his background in astronomy and meteorology. Shifting his gaze from the heavens to the earth, Quetelet arrived at his idea of “the average man” by inverting the standard approach his colleagues used to fix the location of stars, in which the results of observations from multiple observatories (each with some degree of error) were combined to determine a star's most likely celestial coordinates ( Porter 1981 ; Stigler 1986 , 2002 ). Reasoning by analogy, Quetelet ingeniously, if erroneously, argued that the distribution of a population's characteristics served as a guide to its true (inherent) value ( Quetelet 1835 , 1844 ). From this standpoint, the observed “deviations” or “errors” arose from the imperfect variations of individuals, each counting as an “observation-with-error” akin to the data produced by each observatory. The impact of these “errors” was effectively washed out by the law of large numbers. Attesting to the power of metaphor in science and more generally ( Krieger 1994 , 2011 ; Martin and Harré 1982 ; Ziman 2000 ), Quetelet's astronomical “average man” simultaneously enabled a new way to see and study population variation even as it erased a crucial distinction. For a star, the location of the mean referred to the location of a singular real object, whereas for a population, the location of its population mean depended on how the population was defined.
To Quetelet, this new conception of population meant that population means, based on sufficiently large samples, could be meaningfully compared to determine if the populations’ essential characteristics truly differed. The contingent causal inference was that if the specified populations differed in their means, this would mean that they either differed in their essence (if subject to the same external forces) or else were subject to different external forces (assuming the same internal essence). Reflecting, however, the growing pressure for nascent social scientists to be seen as “objective,” Quetelet's discussion of external forces steered clear of politics. Concretely, this translated to not challenging mainstream religious or economic beliefs, including the increasingly widespread individualistic philosophies then linked to the rapid ascendance of the liberal free-market economy ( Desrosières 1998 ; Hacking 1990 ; Heilbron, Magnusson, and Wittrock 1998 ; Porter 1981 , 1986 , 1995 , 2003 ; Ross 2003 ). For example, although Quetelet conceded that “the laws and principles of religion and morality” could act as “influencing causes” ( Quetelet 1844 , xvii), in his analyses he treated education, occupation, and the propensity to commit crime as individual attributes no different from height and weight. The net result was that a population's essence—crucial to its success or failure—was conceptualized as an intrinsic property of the individuals who comprised the population; the corollary was that population means and rates were a result and an expression of innate individual characteristics.
Or so the argument went. At the time, others were not convinced and contended that Quetelet's means were simply arbitrary arithmetic contrivances resulting from declaring certain groups to be populations ( Cole 2000 ; Desrosières 1998 ; Porter 1981 ; Stigler 1986 , 2002 ). As Quetelet himself acknowledged, the national averages and rates defining a country's “average man” coexisted with substantial regional and local variation. Hence, data for one region of France would yield one mean, and for another region it would be something else. If the two were combined, a third mean would result—and who was to say which, if any, of these means was meaningful, let alone reflective of an intrinsic essence (or, for that matter, external influences)?
Quetelet's tautological answer was to differentiate between what he termed “true means” versus mere “arithmetical averages” ( Porter 1981 ; Quetelet 1844 ). The former could be derived only from “true” populations, whose distribution by definition expressed the “law of errors” (e.g., the normal curve). In such cases, Quetelet argued, the mean reflected the population's true essence. By contrast, any disparate lot of objects measured by a common metric could yield a simple “average” (e.g., average height of books or of buildings), but the meaningless nature of this parameter, that is, its inability to be informative about any innate “essence,” would be revealed by the lack of a normal distribution.
And so the argument continued until the terms were changed in a radically different way by Darwin's theory of evolution, presented in Origin of Species , published in 1859 (Darwin [1859] [ 2004 ]). The central conceptual shift was from “errors” to “variation” ( Eldredge 2005 ; Hey 2011 ; Hodge 2009 ; Mayr 1988 ). This variation, thought to reflect inheritable characteristics passed on from parent to progeny, was in effect a consequence of who survived to reproduce, courtesy of “natural selection.” No longer were species, that is, the evolving biological populations to which these individuals belonged, either arbitrary or constant. Instead, they were produced by reproducing organisms and their broader ecosystem. Far from being either Platonic “ideal types” ( Hey 2011 ; Hodge 2009 ; Mayr 1988 ; Weiss and Long 2009 ), per Quetelet's notion of fixed essence plus error, or artificially assembled aggregates capable of yielding only what Quetelet would term meaningless mere “averages,” “populations” were newly morphed into temporally dynamic and mutable entities arising by biological descent. From this standpoint, variation was vital, and variants that were rare at one point in time could become the new norm at another.
Nevertheless, even though the essence of biological populations was now impermanent, what substantively defined “populations” remained framed as fundamentally endogenous. In the case of biological organisms, this essence resided in whatever material substances were transmitted by biological reproduction. Left intact was an understanding of population, population traits, and their variability as innately defined, with this variation rendered visible through a statistical analysis of appropriate population samples. The enduring result was to (1) collapse the distinctions between populations as substantive beings versus statistical objects and (2) imply that population characteristics reflect and are determined by the intrinsic essence of their component parts. Current conventional definitions of “population” say as much and no more ( table 1 ).
Conceptual Criteria for Defining Meaningful Populations for Public Health
Framing and Contesting “Population” through an Epidemiologic Lens . In the 150 years since these initial features of populations were propounded, they have become deeply entrenched, although not entirely uncontested. Figure 2 is a schematic encapsulation of mid-nineteenth to early twentieth-century notions of populations, with the entries emphasizing population statistics and population genetics because of their enduring influence, even now, on conceptions of populations in epidemiology and other population sciences. During this period, myriad disciplines in the life, social, and physical sciences embraced a statistical understanding of “population” ( Desrosières 1998 ; Hey 2011 ; Porter 1981 , 1986 , 2002 , 2003 ; Ross 2003 ; Schank and Twardy 2009 ; Yeo 2003 ). Eugenic thinking likewise became ascendant, espoused by leading scientists and statisticians, especially the newly named “biometricians,” who held that individuals and populations were determined and defined by their heredity, with the role of the “environment” being negligible or nil ( Carlson 2001 ; Davenport 1911 ; Galton 1904 ; Kevels 1985 ; Mackenzie 1982 ; Porter 2003 ; Tabery 2008 ).

A schematic cross-disciplinary genealogy of mid-nineteen to early twentieth-century “population” thinking and current impact.
Sources : Carver 2003 ; Crow 1990 , 1994 ; Dale and Katz 2011 ; Darwin 1859 ; Daston 1987 ; Desrosières 1998 ; Eldredge 2005 ; Galton 1889 , 1904 ; Hacking 1975 , 1990 ; Hey 2011 ; Hodge 2009 ; Hogben 1933 ; Keller 2010 ; Mackenzie 1982 ; Marx 1845 ; Mayr 1988 ; Porter 1981 , 1986 , 2002 , 2003 ; Quetelet 1835 , 1844 ; Sarkar 1996 ; Schank and Twardy 2009 ; Stigler 1986 , 1997 ; Tabery 2008 ; Yeo 2003 .
It was also during the early twentieth century that the nascent academic discipline of epidemiology advanced its claims about being a population science, as part of distinguishing both the knowledge it generated and its methods from those used in the clinical and basic sciences ( Krieger 2000 , 2011 ; Lilienfeld 1980 ; Rosen [1958] [ 1993 ]; Susser and Stein 2009 ; Winslow et al. 1952 ). In 1927 and in 1935, for example, the first professors of epidemiology in the United States and the United Kingdom—Wade Hampton Frost (1880–1938) at the Johns Hopkins School of Hygiene and Public Health in 1921 ( Daniel 2004 ; Fee 1987 ), and Major Greenwood (1880–1949) at the London School of Hygiene and Tropical Medicine in 1928 ( Butler 1949 ; Hogben 1950 )—urged that epidemiology clearly define itself as the science of the “mass phenomena” of disease, Frost in his landmark essay “Epidemiology” (Frost [1927] [ 1941 ], 439) and Greenwood in his discipline-defining book Epidemics and Crowd Diseases: An Introduction to the Study of Epidemiology ( Greenwood 1935 , 125). Neither Frost nor Greenwood, however, articulated what constituted a “population,” other than the large numbers required to make a “mass.”
Also during the 1920s and 1930s, two small strands of epidemiologic work—each addressing different aspects of the inherent dual engagement of epidemiology with biological and societal phenomena ( Krieger 1994 , 2001 , 2011 )—began to challenge empirically and conceptually the dominant view of population characteristics as arising solely from individuals' intrinsic properties. The first thread was metaphorically inspired by chemistry's law of “mass action,” referring to the likelihood that two chemicals meeting and interacting in, say, a beaker, would equal the product of their spatial densities ( Heesterbeek 2005 ; Mendelsohn 1998 ). Applied to epidemiology, the law of “mass action” spurred novel efforts to model infectious disease dynamics arising from interactions between what were termed the “host” and the “microbial” populations, taking into account changes in the host's characteristics (e.g., from susceptible to either immune or dead) and also the population size, density, and migration patterns (Frost [ 1928 ] 1976; Heesterbeek 2005 ; Hogben 1950 ; Kermack and McKendrick 1927 ; Mendelsohn 1998 ).
The second thread was articulated in debates concerning eugenics and also in response to the social crises and economic depression precipitated by the 1929 stock market crash. Its focus concerned how societal conditions could drive disease rates, not only by changing individuals’ economic position, but also through competing interests. Explicitly stating this latter point was the 1933 monograph Health and Environment ( Sydenstricker 1933 ), prepared for the U.S. President's Research Committee on Social Trends by Edgar Sydenstricker (1881–1936), a leading health researcher and the first statistician to serve in the U.S. Public Health Service ( Krieger 2011 ; Krieger and Fee 1996 ; Wiehl 1974 ). In this landmark text, which explicitly delineated diverse aspects of what he termed the “social environment” alongside the physical environment, Sydenstricker argued (1933, 16, italics in original):
Economic factors in the conservation or waste of health, for example, are not merely the rate of wages; the hours of labor; the hazard of accident, of poisonous substances, or of deleterious dusts; they include also the attitude consciously taken with respect to the question of the relative importance of large capitalistic profits versus maintenance of the workers’ welfare.
In other words, social relations, not just individual traits, shape population distributions of health.
Influenced by and building on both Greenwood's and Sydenstricker's work, in 1957 Jeremy Morris (1910–2009) published his highly influential and pathbreaking book Uses of Epidemiology ( Morris 1957 ), which remains a classic to this day ( Davey Smith and Morris 2004 ; Krieger 2007a ; Smith 2001 ). Going beyond Frost and Greenwood, Morris emphasized that “the unit of study in epidemiology is the population or group , not the individual ” ( Morris 1957 , 3, italics in original) and also went further by newly defining epidemiology in relational terms, as “ the study of health and disease of populations and of groups in relation to their environment and ways of living ” ( Morris 1957 , 16, italics in original). As a step toward defining “population,” Morris noted that “the ‘population’ may be of a whole country or any particular and defined sector of it” ( Morris 1957 , 3), as delimited by people's “environment, their living conditions, and special ways of life” ( Morris 1957 , 61). He also, however, recognized that better theorizing about populations was needed and hence called for a greater “understanding of the properties of individuals which they have in virtue of their group membership” ( Morris 1957 , 120, italics in original). But this appeal went largely unheeded, as it directly contradicted the era's prevailing framework of methodological individualism ( Issac 2007 ; Krieger 2011 ; Ross 2003 ).
Morris's insights notwithstanding, the dominant view has remained what is presented in table 1 . Even the recent influential work of Geoffrey Rose (1926–1993), crucial to reframing individual risk in population terms, theorized populations primarily in relation to their distributional, not substantive, properties ( Rose 1985 , 1992 , 2008 ). Rose's illuminating analyses thus emphasized that (1) within a population, most cases arise from the proportionately greater number of persons at relatively low risk, as opposed to the much smaller number of persons at high risk; (2) determinants of risk within populations may not be the same as determinants of risk between populations; and (3) population norms shape where both the tails and the mean of a distribution occur. Rose thus cogently clarified that to change populations is to change individuals, and vice versa, implying that the two are mutually constitutive, but he left unspecified who and what makes meaningful populations and when they can be meaningfully compared.
Current Challenges to Conventional Views of “Population.” A new wave of work contesting the still reigning idea of “the average man” can currently be found in recent theoretical and empirical work in the social and biological sciences attempting to analyze population phenomena in relation to dynamic causal processes that encompass multiple levels and scales, from macro to micro ( Biersack and Greenberg 2006 ; Eldredge 1999 ; Eldredge and Grene 1992 ; Gilbert and Epel 2009 ; Grene and Depew 2004 ; Harraway 2008 ; Illari, Russo, and Williamson 2011 ; Krieger 2011 ; Lewontin 2000 ; Turner 2005 ). Also germane is research on system properties in the physical and information sciences ( Kuhlmann 2011 ; Mitchell 2009 ; Strevens 2003 ).
Applicable to the question of who and what makes a population, one major focus of this alternative thinking is on processes that generate, maintain, transform, and lead to the demise of complex entities. This perspective builds on and extends a long history of critiques of reductionism ( Grene and Depew 2004 ; Harré 2001 ; Illari, Russo, and Williamson 2011 ; Lewontin 2000 ; Turner 2005 ; Ziman 2000 ), which together aver that properties of a complex “whole” cannot be reduced to, and explained solely by, the properties of its component “parts.” The basic two-part argument is that (a) new (emergent) properties can arise out of the interaction of the “parts” and (b) properties of the “whole” can transform the properties of their parts. Thus, to use one well-known example, a brain can think in ways that a neuron cannot. Taking this further in regard to the generative causal processes at play, what a brain thinks can affect neuron connections within the brain, and it also is affected by the ecological context and experiences of the organism, of which the brain is a part ( Fox, Levitt, and Nelson 2010 ; Gibson 1986 ; Harré 2001 ; Stanley, Phelps, and Banaji 2008 ). The larger claim is that the causal processes that give rise to complex entities can both structure and transform the characteristics of both the whole and its parts.
What might it look like for public health to bring this alternative perspective to the question of defining, substantively, who and what makes a population? Let me start with a conceptual answer, followed by some concrete public health propositions and examples.
Populations as Relational Beings: An Alternative Causal Conceptualization
In brief, I argue that a working definition of “populations” for public health (or any field concerned with living organisms) would, in line with Sydenstricker (1933) and Morris (1957) and the other contemporary theorists just cited, stipulate that populations are first and foremost relational beings, not “things.” They are active agents, not simply statistical aggregates characterized by distributions.
Specifically, as tables 2 and 3 show, the substantive populations that populate our planet
Conceptual Criteria for Defining Meaningful Populations for Population Sciences, Guided by the Ecosocial Theory of Disease Distribution
Source: Krieger 1994 , 2001 , and 2011 , 214–15.
Defining Features of Populations of Living Beings, Including Humans, Relevant to Public Health and Population Sciences
| Intrinsic (Constitutive) Relationships (Internal and External) | ||||||
|---|---|---|---|---|---|---|
| Example | Boundaries | Individuals | Genealogical | Internal and Economical: Relationships among Individuals in the Population | External and Ecological: With Other Populations | Teleological (for Humans and Possibly Some Other Species) |
| Human beings: U.S. population | Political and geographic, i.e., nation-state with citizenship criteria established by politics and territory; although “cultural” boundaries also exist, they are predicated on nationality. | Individual persons, in legally defined groups demarcated by historically contingent citizenship status: (a) U.S. free nonindigenous citizens ; (b) U.S. indigenous citizens (who may have legally defined dual citizenship with sovereign tribal nations); and (c) noncitizens: legal “permanent residents” (and “permanent aliens” ), legally defined refugees, and undocumented persons. | Direct genealogy: U.S. citizenship by being born to U.S. citizens ( ); citizenship by place of birth ( , for persons not otherwise born to U.S. citizens) can become genealogical citizenship for subsequent generations. | As in any polity (political-geographic entity), the economic, legal, political, and social relationships in the United States between individuals that produce, reproduce, and transform the daily conditions of life (e.g., involving work, commerce, property, and the production, exchange and consumption of material goods; establishing and maintaining family life from birth to death), which individuals are legally permitted to engage in these relationships is historically contingent (e.g., banning of child labor in the early 20th century; legal racial discrimination in employment and housing until the mid-1960s; current legal restriction of marriage to heterosexual couples in most U.S. states) | U.S. foreign and domestic policy, along with international treaties the United States has signed, shape political, territorial, legal, social, economic, cultural, and ecosystem relationships both (a) between the U.S. population and populations elsewhere in the world (including who is and is not allowed to immigrate, cf. the 1882 Chinese exclusion act and the 1924 immigration restriction act) and (b) within the United States. | U.S. domestic and foreign policy sets parameters of who counts as the U.S. population and the conditions in which the U.S. population (and its component groups) lives. |
| Human beings: Social classes | Economic, political, and legal, set by rules and relationships involving property and labor (within and across boundaries of nation-states). | Individual persons and/or individuals in households and/or family structures that live as an economic unit. | Direct genealogy: class origins at birth; political system and legal rules determine if class position is solely hereditary or if class mobility is allowed. | Social classes are established and maintained through their intrinsic relationships to one another as established by the prevailing political system and its legal rules involving property and labor (e.g., cannot have employer without employee); individuals within particular classes can form groups to advance their class interest (whether in conflict or cooperation with the other classes). | Political, legal, and economic relationships among social classes generated by underlying political economy, shaping ways of living, and rights of each social class. | Political philosophies and economic interests shape how individuals view social classes and act to maintain or alter the political and economic systems that give rise to them. |
| Populations within human beings: human cells and the microbiome | Biological: cell surfaces (and surfaces of cells as organized in tissues, and of tissues as organized in organs). | Human cells (∼10% of cells within a human) and microbial cells (∼90% of the cells within and on a human). | Human cells: from fertilized ovum. Microbiome: initiated by exposure to mother's microbial ecology via birth (vaginal if vaginal delivery, epidermal if Cesarean section); bacteria then primarily reproduce asexually and new bacteria may be introduced (e.g., by fecal-oral transmission). | Example of gut microbiome: symbiotic (mutualistic) extension of human gut cell faculties, in which diverse types of bacteria (represented by different phyla and their species in the oral cavity, stomach, small intestine, and large intestine) receive (and compete for) nourishment, aid with digestion, produce vitamins, and modulate inflammatory response. | Relationships within and on body: among bacteria (intraspecies, interspecies, and gene transfer) and with human cells. Relationships across body boundary: exposure to exogenous bacteria. | Deliberate alteration of microbiome composition by use of antibiotics, probiotics, changes in diet, and changes in water supply and sanitation. |
| Nonhuman population: example of the eastern cottonwood ( ), a hardwood tree native to North America that grows best near streams, and one of 35+ tree species that are poplars. | Biological: a tree species, one that has the ability to produce hybrids with other species in the same genus, including , whose genome was sequenced in 2006, thereby establishing it as the first tree model system for plant biology. | Individual tree (dioecious, i.e., tree is typically female or male). | Sexual reproduction: via wind-driven pollination of flowers on female tree by pollen from flowers on male tree (whereby a female tree may annually produce millions of seeds fertilized by pollen from thousands of male trees), and the seeds (which have long wispy tufts, resembling cotton) are dispersed by both wind and water. Asexual reproduction: via broken branches (e.g., due to storms and floods); people can also propagate via unrooted cuttings. | Typically grows in pure stands, with dominant trees determining spacing between trees (since the trees are very intolerant of shade). Communication to counter predation: self-signaling and between-tree communication via plant volatiles (airborne chemicals) released by herbivore-damaged leaves (e.g., eaten by gypsy moth larvae) that prime defenses (e.g., to attract parasitoids that prey on the larvae) in other leaves (within tree and, if close enough, those of adjacent trees). | In ecosystem context of growing in riverine environment (flood plains with alluvial soil), relationships with —insect predators, —fungal pathogens: —herbivores (e.g., rabbits, deer, and livestock, who both browse and trample the seedlings and saplings) —other animals (e.g., beavers, which build dams out of the saplings; cavities in living cottonwoods used for nesting and winter shelter by wood ducks, woodpeckers, owls, opossums, raccoons) —other tree species: compete with willows (which grow in same areas). | Nontelological (on part of trees) but can be affected by purpose-driven animal behavior (e.g., beavers fell poplars for dams) and by human activity (e.g., human damming and diversions of river waters). |
Before Emancipation, neither U.S. slaves nor their children were granted citizenship rights, and they became citizens only after passage of the 1866 Bill of Rights and, in 1868, the Fourteenth Amendment ( Steinman 2011 ).
It was not until 1924 that the U.S. government extended citizenship to all American Indians born within the territorial limits of the United States; reflecting this change, in the 1930 census the terminology shifted from Indians “in” the USA to Indians “of” the USA. Before 1924, the status of “citizen” was applied only to those American Indians granted citizenship by specific treaties, naturalization proceedings, and military service in World War I ( Steinman 2011 ).
The 1882 Chinese exclusion act, which banned Chinese immigration for 10 years and also imposed new restrictions on reentry (including reassignment from citizen to “permanent alien”) was renewed repeatedly and reversed only in 1943. The 1924 Immigration Act, designed to control “undesirable immigration” (especially by Jews and also by Asians), set quotas and restrictions (in relation to the U.S. composition, by national origins, in 1880) that were in effect until 1965 ( Foner 1997 ; Zinn 2003 ).
According to the U.S. government, the criterion “to become a citizen at birth” is that the person must “have been born in the United States or certain territories or outlying possessions of the United States, and subject to the jurisdiction of the United States; OR had a parent or parents who were citizens at the time of your birth (if you were born abroad) and meet other requirements; people can also become a citizen after birth if they “apply for ‘derived’ or ‘acquired’ citizenship through parents” or “apply for naturalization” ( U.S. Citizenship and Immigration Services 2012 ). For discussion of the changing complexities of conceptualizing and defining nation-states and who counts as belonging to them, see Wimmer and Schiller 2002 .
Are animate, self-replicating, and bounded complex entities, generated by systemic causal processes.
Arise from and are constituted by relationships of varying strengths, both externally (with and as bounded by other populations) and internally (among their component beings).
Are inherently constituted by, and simultaneously influence the characteristics of, the varied individuals who comprise its members and their population-defined and -defining relationships.
It is these relationships and their underlying causal processes (both deterministic and probabilistic), not simply random samples derived from large numbers, that make it possible to make meaningful substantive and statistical inferences about population characteristics, as well as meaningful causal inferences about observed associations.
Accordingly, as summarized by Richard A. Richards, a philosopher of biology (who was writing about species, one type of population), populations have “well-defined beginnings and endings, and cohesion and causal integration” ( Richards 2001 ). They likewise necessarily exhibit historically contingent distributions in time and space, by virtue of the dynamic interactions intrinsically occurring between (and within) their unique individuals and with other equally dynamic codefining populations and also their changing abiotic environs. Underscoring this point, even a population of organisms cloned from a single source organism will exhibit variation and distributions as illustrated by the phenomenon of developmental “noise,” an idea presaged by early twentieth-century observations of chance differences in coat color among litter mates of pure-bred populations raised in identical circumstances ( Davey Smith 2011 ; Lewontin 2000 ; Wright 1920 ).
As for the inherent relationships characterizing populations, both internally and externally, I suggest that four key types stand out, as informed by the ecosocial theory of disease distribution ( Krieger 1994 , 2001 , 2011 ); the collaborative writing of Niles Eldredge, an evolutionary biologist, and Marjorie Grene, a philosopher of biology ( Eldredge and Grene 1992 ); as well as works from political sociology, political ecology, and political geography ( Biersack and Greenberg 2006 ; Harvey 1996 ; Nash and Scott 2001 ). As tables 2 and 3 summarize, these four kinds of relationships are (1) genealogical , that is, relationships by biological descent; (2) internal and economical, in the original sense of the term, referring to relationships essential to the daily activities of whatever is involved in maintaining life (in ancient Greece, oikos , the root of the “eco” in both “ecology” and “economics,” referred to a “household,” conceptualized in relation to the activities and interactions required for its existence [ OED 2010]); (3) external and ecological , referring to relationships between populations and with the environs they coinhabit; and (4) in the case of people (and likely other species as well), teleological , that is, by design, with some conscious purpose in mind (e.g., citizenship criteria). Spanning from mutually beneficial (e.g., symbiotic) to exploitative (benefiting one population at the expense of the other), these relationships together causally shape the characteristics of populations and their members.
What are some concrete examples of animate populations that exemplify these points? Table 3 provides four examples. Two pertain to human populations: the “U.S. population” ( Foner 1997 ; Zinn 2003 ) and “social classes” ( Giddens and Held 1982 ; Wright 2005 ). The third considers microbial populations within humans ( Dominguez-Bello and Blaser 2011 ; Pflughoeft and Versalovic 2012 ; Walter and Ley 2011 ), and the fourth concerns a plant population, a species of tree, the poplar, whose genus name ( Populus ) derives from the same Latin root as “population” ( Braatne, Rood, and Heillman 1996 ; Fergus 2005 ; Frost et al. 2007 ; Jansson and Douglas 2007 ). Together, these examples clarify what binds—as well as distinguishes—each of these dynamic populations and their component individuals. They likewise underscore that contrary to common usage, “population” and “individual” are not antonyms. Instead, they hark back to the original meaning of “individual”—that is, “individuum,” or what is indivisible, referring to the smallest unit that retained the properties of the whole to which it intrinsically belonged ( OED 2010; Williams 1985 ). Thus, although it is analytically possible to distinguish between “populations” and “individuals,” in reality these phenomena occur and are lived simultaneously. A person is not an individual on one day and a member of a population on another. Rather, we are both, simultaneously. This joint fact is fundamental and is essential to keep in mind if analysis of either individual or population phenomena is to be valid.
The importance of considering the intrinsic relationships—both internal and external—that are the integuments of living populations, themselves active agents and composed of active agents, is further illuminated through contrast to the classic case of a hypothetical population: the proverbial jar of variously colored marbles, used in many classes to illustrate the principles of probability and sampling. Apart from having been manufactured to be of a specific size, density, and color, there are no intrinsic relationships between the marbles as such. Spill such a jar, and see what happens.
As this thought experiment makes clear, the marbles will not reconstitute themselves into any meaningful relationships in space or time. They will just roll to wherever they do, and that will be the end of it, unless someone with both energy and a plan scoops them up and puts them back in the jar. Nor will a sealed jar of marbles change its color composition (i.e., the proportion of marbles of a certain color), or an individual marble change its color, unless someone opens the jar and replaces, adds, or removes some marbles or treats them with a color-changing agent. Hence, a purely statistical understanding of “populations,” however necessary for sharpening ideas about causal inference, study design, and empirical estimation, is by itself insufficient for defining and analyzing real-life populations, including “population health.”
That said, marbles do have their uses. In particular, they can help us visualize how causal determinants can structure population distributions of the risks of random individuals via what I term “structured chances.”
Populations and Structured Chances
One long-standing conundrum in population sciences is their ability to identify and use data on population regularities to elucidate causal pathways, even though they cannot predict which individuals in the population will experience the outcome in question ( Daston 1987 ; Desrosières 1998 ; Hacking 1990 ; Illari, Russo, and Williamson 2011 ; Porter 1981 , 2002 , 2003 ; Quetelet 1835 ; Stigler 1986 ; Strevens 2003 ). This incommensurability of population and individual data has been a persistent source of tension between epidemiology and medicine (Frost [1927] [ 1941 ]; Greenwood 1935 ; Morris 1957 ; Rose 1992 , 2008 ). Epidemiologic research, for example, routinely uses aggregated data obtained from individuals to gain insight into both disease etiology and why population rates vary, and does so with the understanding that such research cannot predict which individual will get the disease in question ( Coggon and Martyn 2005 ). By contrast, medical research remains bent on using just these sorts of data to predict an individual's risk, as exemplified in its increasingly molecularized quest for “personalized medicine” ( Davey Smith 2011 ).
Where marbles enter the picture is that they can, through the use of a physical model, demonstrate the importance of how population distributions are simultaneously shaped by both structure (arising from causal processes) and randomness (including truly stochastic events, not just “randomness” as a stand-in for “ignorance” of myriad deterministic events too complex to model). As Stigler has recounted (1997), perhaps the first person to propose using physical models to understand probability was Sir Francis Galton (1822–1911), a highly influential British scientist and eugenicist ( figure 2 ), who himself coined the term “eugenics” and who held that heredity fundamentally trumped “environment” for traits influencing the capacity to thrive, whether physical, like health status, or mental, like “intelligence” ( Carlson 2001 ; Cowan 2004 ; Galton 1889 , 1904 ; Keller 2010 ; Kevels 1985 ; Stigler 1997 ). In his 1889 opus Natural Inheritance ( Galton 1889 ), Galton sketched ( figure 3 ) “an apparatus … that mimics in a very pretty way the conditions on which Deviation depends” ( Galton 1889 , 63), whereby gun shots (i.e., marble equivalents) would be poured through a funnel down a board whose surface was studded with carefully placed pins, off which each pellet would ricochet, to be collected in evenly spaced bins at the bottom.

Producing population distributions: structured chances as represented by physical models.
Sources: Galton's Quincunx, Galton 1889 , 63; physical models, Limpert, Stahel, and Abbt 2001 (reproduced with permission).
Galton termed his apparatus, which he apparently never built ( Stigler 1997 ), the “Quincunx” because the pattern of the pins used to deflect the shot was like a tree-planting arrangement of that name, which at the time was popular among the English aristocracy ( Stigler 1997 ). The essential point was that although each presumably identical ball had the same starting point, depending on the chance interplay of which pins it hit during its descent at which angle, it would end up in one or another bin. The accumulation of balls in any bin in turn would reflect the number of possible pathways (i.e., likelihood) leading to its ending up in that bin. Galton designed the pin pattern to yield a normal distribution. He concluded that his device revealed ( Galton 1889 , 66)
a wonderful form of cosmic order expressed by the “Law of Frequency of Error.” The law would have been personified by the Greeks and deified, if they had known of it. It reigns with serenity and in complete self-effacement amidst the wildest confusion. The huger the mob, and the greater the apparent anarchy the more perfect is its sway … each element, as it is sorted into place, finds, as it were, a pre-ordained niche, accurately adapted to fit it.
In other words, in accord with Quetelet's view of “l’homme moyen,” Galton saw the order produced as the property of each “element,” in this case, the gun shot.
However, a little more than a century later, some physicists not only built Galton's “Quincunx,” as others have done ( Stigler 1997 ), but went one further ( Limpert, Stahel, and Abbt 2001 ): they built two, one designed to generate the normal distribution and the other to generate the log normal distribution (a type of distribution skewed on the normal scale, but for which the natural logarithm of the values displays a normal distribution) ( figure 3 ). As their devices clearly show, what structures the distribution is not the innate qualities of the “elements” themselves but the features of both the funnel and the pins—both their shape and placement. Together, these structural features determine which pellets can (or cannot) pass through the pins and, for those that do, their possible pathways.
The lesson is clear: altering the structure can change outcome probabilities, even for identical objects, thereby creating different population distributions. For the population sciences, this insight permits understanding how there can simultaneously be both chance variation within populations (individual risk) and patterned differences between population distributions (rates). Such an understanding of “structured chances” rejects explanations of population difference premised solely on determinism or chance and also brings Quetelet's astronomical “l’homme moyen” and its celestial certainties of fixed stars back down to earth, grounding the study of populations instead in real-life, historically contingent causal processes, including those structured by human agency.
Rethinking the Meaning and Making of Means: The Utility of Critical Population-Informed Thinking
How might a more critical understanding of the substantive nature of real-life populations benefit research on, knowledge about, and policies regarding population health and health inequities? Drawing on table 2 's conceptual criteria for defining who and what makes populations, table 4 offers four sets of critical public health propositions about “populations” and “study populations,” whose salience I assess using examples of breast cancer, a disease increasingly recognized as a major cause of morbidity and mortality in both the global South and the global North ( Althuis et al. 2005 ; Bray, McCarron, and Parkin 2004 ; Parkin and Fernández 2006 ) and one readily revealing that the problem of meaningful means is as vexing for “the average woman” as for “the average man.”
Four Propositions to Improve Population Health Research, Premised on Critical Population-Informed Thinking
| Proposition 1. Stating what should be obvious: the meaningfulness of means to provide insights into health-related population characteristics and their generative causal processes depends on how meaningfully the populations are defined in relation to the inherent intrinsic and extrinsic dynamic generative relationships by which they are constituted. |
| Corollary 1.1. A critical appraisal of the validity and meaning of estimated “population rates” of health-related phenomena (whether based on registry, survey, or administrative data or generated by mathematical models) requires an explicit recognition of populations as inherently relational beings. |
| Corollary 1.2. A critical comparison of population rates of health-related phenomena (at a given point in time or over time), and a formulation of hypotheses to explain observed differences and similarities, likewise requires an explicit recognition of populations as inherently relational beings. |
| Proposition 2. Structured chances—structured by a population's constitutive intrinsic and extrinsic dynamic relationships—drive population distributions of health, disease, and well-being, including (a) on-average rates, (b) the magnitude of health inequities, and (c) their change or persistence over time. |
| Corollary 2.1. Health inequities, arising out of population dynamics, are historically contingent, so that the risks associated with variables intended to serve as markers for structural determinants of health should be expected to vary by time and place. |
| Corollary 2.2. The manifestation of health, disability, and disease, at both the population level and the individual level, should be conceptualized as embodied phenotypes, not decontextualized genotypes. |
| Proposition 3. To improve scientific accuracy and promote critical thinking, persons used in population health studies should be referred to as “study participants,” not the “study population,” and whether they meet criteria for being a meaningful “population” should be explained, not presumed. |
| Corollary 3.1. Texts describing the study participants should—in addition to explaining the methods used to identify and include them—explicitly situate them in relation to the inherent intrinsic and extrinsic dynamic relationships constituting the society (or societies) in which they are based. |
| Corollary 3.2. If study participants are identified by methods using probability samples, the defining characteristics of the sampled populations must be explicated in relation to the intrinsic and extrinsic dynamic relationships constituting the population(s) at issue. |
| Proposition 4. The conventional cleavage of “internal validity” and “generalizability” is misleading, since a meaningful choice of study participants must be in relation to the range of exposures experienced (or not) in the real-world societies, that is, meaningful populations, of which they are a part. |
| Corollary 4.1. Although studies do not need to be “representative” to generate valid results regarding exposure-outcome associations, a critical appraisal of the observed associations requires situating the observed distribution (on-average level and range) of exposures and outcomes in relation to distributions observed among populations defined by the intrinsic and extrinsic dynamic relationships in the society (or societies) in which the study participants are based. |
| Corollary 4.2. The restriction of studies to “easy-to-reach” populations can, owing to selection bias, produce biased estimates of risk, lead to invalid causal inferences, and hamper the discovery of needed etiologic and policy-relevant knowledge. |
Propositions 1 and 2: Critically Parsing Population Rates and Their Comparisons
Consider, first, three illustrative cases pertaining to analyses of population rates of breast cancer:
A recent high-profile analysis of the global burden of breast cancer ( Briggs 2011 ; Forouzanafar et al. 2011 ; IHME 2011; Jaslow 2011 ), which estimated and compared rates across countries, accompanied by interpretative text, with the article stating, for example, that Colombia and Venezuela “… have very different trends, despite sharing many of the same lifestyle and demographic factors,” followed by the inference that the “explanation of these divergent trends may lie in the interaction between genes and individual risk factors.” (IHME 2011, 24)
Typical reviews of the global epidemiology of breast cancer, which contain such statements as “Population-based statistics show that globally, when compared to whites, women of African ancestry (AA) tend to have more aggressive breast cancers that present more frequently as estrogen receptor negative (ERneg) tumors” ( Dunn et al. 2010 , 281); and “early onset ER negative tumors also develop more frequently in Asian Indian and Pakistani women and in women from other parts of Asia, although not as prevalent as it is in West Africa.” ( Wallace, Martin, and Ambs 2011 , 1113)
The headline-making news that the U.S. breast cancer incidence rate in 2003 unexpectedly dropped by 10 percent, a huge decrease ( Kolata 2006 , 2007 ; Ravdin et al. 2006 , 2007 ).
What these three commonplace examples have in common is an uncritical approach to presenting and interpreting population data, premised on the dominant assumption that population rates are statistical phenomena driven by innate individual characteristics. Cautioning against accepting these claims at face value are propositions 1 and 2, with their emphases, respectively, on (1) critically appraising who constitutes the populations whose means are at issue and (2) critically considering the dynamic relationships that give rise to population patterns of health, including health inequities.
From the standpoint of proposition 1, the first relevant fact is that as a consequence of global disparities in resources ( Klassen and Smith 2011 ) arising from complex histories of colonialism and underdevelopment ( Birn, Pillay, and Holtz 2009 ), only 16 percent of the world's population is covered by cancer registries, with coverage of less than 10 percent within the world's most populous regions (Africa, Asia [other than Japan], Latin America, and the Caribbean), versus 99 percent in North America ( Parkin and Fernández 2006 ). Put in national terms, among the 184 countries for which the International Agency on Cancer (IARC) reports estimated rates, only 33 percent—almost all located in the global North—have reliable national incidence data ( GLOBOCAN 2012 ). These data limitations are candidly acknowledged both by IARC ( GLOBOCAN 2012 ) and in the scientific literature, including that on breast cancer ( Althuis et al. 2005 ; Bray, McCarron, and Parkin 2004 ; Ferlay et al. 2012 ; Krieger, Bassett, and Gomez 2012 ; Parkin and Fernández 2006 ). To generate estimates of incidence in countries lacking national cancer registry data, the IARC transparently employs several modeling approaches, based on, for example, a country's national mortality data combined with city-specific or regional cancer registry data (if they do exist, albeit typically not including the rural poor) or, when no credible national data are available, estimating rates based on data from neighboring countries ( GLOBOCAN 2012 ).
A critical analysis of the population claims asserted in examples 1 and 2 starts by questioning whether the means at issue can bear the weight of meaningful comparisons and inference. Thus, relevant to example 1, Colombia has only one city-based cancer registry (in Cali), and Venezuela has no cancer registries at all ( GLOBOCAN 2012 ). Moreover, the rates compared ( Forouzanafar et al. 2011 ; IHME 2011 ) were generated by nontransparent modeling methods ( Krieger, Bassett, and Gomez 2012 ) that have empirically been shown not to estimate accurately the actually observed rates in the “gold-standard” Nordic countries, known for their excellent cancer registration data ( Ferlay et al. 2012 ). Second, relevant to the countries and geographic regions listed in example 2, the cancer incidence rates estimated by IARC are based (a) for Pakistan, solely on the weighted average for observed rates in south Karachi, (b) for India, on a complex estimation scheme for urban and rural rates in different Indian states and data from cancer registries in several cities, and (c) for western Africa, on the weighted average of data for sixteen countries, of which ten have incidence rates estimated based on those of neighboring countries, another five rely on data extrapolated from cancer registry data from one city (or else city-based cancer registries in neighboring countries), and only one of which has a national cancer registry ( GLOBOCAN 2012 ). Critical thinking about who and what makes a population thus prompts questions about whether the data presented in examples 1 and 2 can provide insight into either alleged individual innate characteristics or into what the true on-average rate would be if everyone were counted (let alone what the variability in rates might be across social groups and regions). There is nothing mundane about a mean.
Proposition 2 in turn calls attention to structured chance in relation to the dynamic intrinsic and extrinsic relationships constituting national populations, with table 2 illustrating what types of relationships are at play using the example of the United States. It thus spurs critical queries as to whether observed national and racial/ethnic differences (if real, and not an artifact of inaccurate data) arise from innate (i.e., genetic) differences between “populations,” as posed by examples 1 and 2. Two lines of evidence alternatively suggest these population differences could instead be embodied inequalities ( Krieger 1994 , 2000 , 2005 , 2011 ; Krieger and Davey Smith 2004 ) that arise from structured chances. The first line pertains to well-documented links among national, racial/ethnic, and socioeconomic inequalities in breast cancer incidence, survival, and mortality ( Klassen and Smith 2011 ; Krieger 2002 ; Vona-Davis and Rose 2009 ). The second line stems from research that evaluates claims of intrinsic biological difference by examining their dynamics, as illustrated by the first investigation to test statistically for temporal trends in the white/black odds ratio for ER positive breast cancer between 1992 and 2005, which revealed that in the United States, the age-adjusted odds ratio rose between 1992 and 2002 and then leveled off (and actually fell among women aged fifty to sixty-nine) ( Krieger, Chen, and Waterman 2011 ).
Relevant to example 3, these findings of dynamic, not fixed, black/white risk differences for breast cancer ER status likely reflect the socially patterned abrupt decline in hormone therapy use following the July 2002 release of results from the U.S. Women's Health Initiative (WHI) ( Rossouw et al. 2002 ). This was the first large randomized clinical trial of hormone therapy, despite its having been widely prescribed since the mid-1960s ( Krieger 2008 ). The WHI found that contrary to what was expected, hormone therapy did not decrease (and may have raised) the risk of cardiovascular disease, and at the same time, the WHI confirmed prior evidence that long-term use of hormone therapy increased the risk of breast cancer (especially ER+). Thus, before the initiative, hormone therapy use in the United States was highest among white women with health insurance who could afford, and were healthy enough, to take the medication without any contraindications ( Brett and Madans 1997 ; Friedman-Koss et al. 2002 ). Population-informed thinking would thus predict that any drops in breast cancer incidence would occur chiefly among those sectors of women most likely to have used hormone therapy. Subsequent global research has borne out these predictions ( Zbuk and Anand 2012 ), including the sole U.S. study that systematically explored socioeconomic differentials both within and across racial/ethnic groups, which found that the observed breast cancer decline was restricted to white non-Hispanic women with ER+ tumors residing in more affluent counties ( Krieger, Chen, and Waterman 2010 ). These results counter the widely disseminated and falsely reassuring impression that breast cancer risk was declining for everyone ( Kolata 2006 , 2007 ). They accordingly provide better guidance to public health agencies, clinical providers, and breast cancer advocacy groups regarding trends in breast cancer occurrence among the real-life populations they serve.
Together, these examples illuminate why proposition 2's corollary 2.2 proposes conceptualizing the jointly lived experience of population rates and individual manifestations of health, disease, and well-being as what I would term “embodied phenotype.” Inherently dynamic and relational, this proposed construct meaningfully links the macro and micro, and populations and individuals, through the play of structured chance. It also is consonant with new insights emerging from the fast-growing field of ecological evolutionary developmental biology (“eco-evo-devo”) into the profound and dynamic links among environmental exposures, gene expression, development, speciation, and the flexibility of organisms’ phenotypes across the life span ( Gilbert and Epel 2009 ; Piermsa and van Gils 2011 ; West-Eberhard 2003 ). Only just beginning to be integrated into epidemiologic theorizing and research ( Bateson and Gluckman 2012 ; Davey Smith 2011 , 2012 ; Gilbert and Epel 2009 ; Kuzawa 2012 ; Relton and Davey Smith 2012 ), eco-evo-devo's historical and relational approach to biological expression affirms the need for critical population-informed thinking.
Propositions 3 and 4: Study Participants, Study Populations, and Causal Inference
Finally, a population-informed approach helps clarify, in accordance with propositions 3 and 4, why improving our understanding of “study populations,” and thus study participants, matters for causal inference. Consider, for example, the 1926 pathbreaking epidemiologic study of breast cancer conducted by the British physician and epidemiologist Janet Elizabeth Lane-Claypon (1877–1967) ( Lane-Claypon 1926 ), the first study to identify systematically what were then called “antecedents” of breast cancer (today termed “risk factors”) and now also widely acknowledged to be the first epidemiologic case-control study, as well as the first epidemiologic study to publish its questionnaire ( Press and Pharoah 2010 ; Winkelstein 2004 ). Quickly replicated in the United States in 1931 by Wainwright ( Wainwright 1931 ), these two studies have recently been reanalyzed, using current statistical methods. The results show that their estimates of risk associated with major reproductive risk factors (e.g., early age at first birth, parity, lactation, and early age at menopause) are consistent with the current evidence ( Press and Pharoah 2010 ).
Not addressed in the reanalysis, however, are the two studies’ different results for occupational class, defined in relation to the women's employment before marriage. When these occupational data are recoded into the meaningful categories of professional, working-class nonmanual, and working-class manual ( Krieger, Williams, and Moss 1997 ; Rose and Pevalin 2003 ), the data quickly reveal why the studies had discrepant results. Thus, Lane-Claypon concluded there was no “appreciable difference” in breast cancer risk by social class ( Lane-Claypon 1926 , 12) (χ 2 = 1.833; p = 0.4), whereas in the U.S. study risk was lower among the working-class manual women (χ 2 = 9.305; p = 0.01). Why? In brief, a far higher proportion of the British women were working-class manual (78.7% cases, 84.2% controls vs. the U.S. women: 48.8% cases, 62.5% controls), and a far lower proportion were professionals (6.5% cases, 4.2% controls, vs. the U.S. women: 23.8% cases, 20.7% controls). Just as Rose famously observed that if everyone smoked, smoking would not be identified as a cause of lung cancer ( Rose 1985 , 1992 ), when most study participants are from only one social class, socioeconomic inequalities in health cannot and will not be detected ( Krieger 2007b ). The net result is erroneous causal inferences about the relevance of social class to structuring the risk of disease, thereby distorting the evidence base informing efforts to address health inequities.
Critical population-informed thinking therefore would question the dominant conventional cleavage, in both the population health and the social sciences, between “internal validity” and “generalizability” (or “external validity”) and the related endemic language of “study population”—routinely casually equated with study participants—and “general population” ( Broadbent 2011 ; Cartwright 2011 ; Cook 2001 ; Kincaid 2011 ; Kukuall and Ganguli 2012 ; Porta 2008 ; Rothman, Greenland, and Lash 2008 ). One critical determinant of a study's ability to provide valid tests of exposure-outcome hypotheses is the range of exposure encompassed ( Chen and Rossi 1987 ; Schlesselman and Stadel 1987 ); another is the extent to which participants’ selection into a study is associated with important unmeasured determinants of the outcome ( Pizzi et al. 2011 ). Given the social structuring of the vast majority of exposures, as evidenced by the virtually ubiquitous and dynamic societal patternings of disease ( Birn, Pillay, and Holtz 2009 ; Davey Smith 2003 ; Krieger 1994 , 2011 ; WHO 2008), meaningful research requires that the range of exposures experienced (or not) by study participants needs to capture the etiologically relevant range experienced in the real-world societies, that is, meaningful populations, of which they are a part. The point is not that ideal study participants should be a random sample of some “general population”; instead, it is that their location in the intrinsic and extrinsic relationships creating their population membership cannot be ignored.
Highlighting the need for critical population-informed thinking is advice provided in the widely used and highly influential textbook Modern Epidemiology ( Rothman, Greenland, and Lash 2008 ). Although the text correctly states that “the pursuit of representativeness can defeat the goal of validly identifying causal relations,” it further asserts that “one would want to select study groups for homogeneity with respect to important confounders, for highly cooperative behavior, and for availability of accurate information, rather than attempt to be representative of a natural population” (p. 146). “Classic examples” of the populations fulfilling these criteria are stated to be “the British Physicians’ Study of smoking and health and the Nurses’ Health Study, neither of which were remotely representative of the general population with respect to sociodemographic factors” ( Rothman, Greenland, and Lash 2008 , 146–47).
Of course, studies need accurate data, but the advice here raises more questions than it answers. First, just who and what is a “natural population”?—and, related, who is that “general population”? Second, might there be drawbacks to, not just benefits from, preferentially studying predominantly white health professionals and others with the resources to be “highly cooperative” and possess “accurate information”? Stated another way, what might be the adverse consequences on scientific knowledge and policymaking of discounting people that mainstream research already routinely and problematically calls “hard-to-reach” populations ( Crosby et al. 2010 ; Shaghaghi, Bhopal, and Sheik 2011 )? These populations include the disempowered and dispossessed, whose adverse social and physical circumstances mean that their range of exposures almost invariably differ, in both level and type, from those encountered by the effectively “easy-to-reach.” Might it not also be critical for researchers to develop more inclusive approaches that could yield accurate etiologic and policy-relevant data on the distributions and determinants of disease among those who bear the brunt of health inequities ( Smylie et al. 2012 )?—a scientific task that necessarily requires contrasts in both exposures and outcomes between the social groups defined by the inequitable societal relationships at issue, whether involving social class, racism, gender, or other forms of social inequality ( Krieger 2007b ).
Reflecting on how who is studied determines what can be learned, the eminent British biologist Lancelot Hogben (1895–1975) ( figure 2 ; Bud 2004 ; Werskey 1988 ), in his lucid and prescient 1933 book titled Nature and Nurture ( Hogben 1933 , 106), cogently observed:
Differences to which members of the same family or different families living at one and the same social level are exposed may be very much less than differences to which individuals belonging to families taken from different social levels are exposed. Experiment shows that ultra-violet light has a considerable influence on growth in mammals. In Great Britain, some families live continuously in the sooty atmosphere of an industrial area. Others spend their winters on the Riviera.
In other words, critical population-informed thinking is vital to good science.
Conclusion: Meaningful Means, Embodied Phenotypes, and the Structural Determinants of Populations and the People's Health
In conclusion, to improve causal inference and policies and action based on this knowledge, the population sciences need to expand and deepen theorizing about who and what makes populations and their means. At a time when the topic of causality in the sciences remains hotly debated by philosophers and researchers alike, all parties nevertheless agree that “the question of how probabilistic accounts of causality can mesh with mechanistic accounts of causality desperately needs answering” ( Illari, Russo, and Williamson 2011 , 20). As my article makes clear, the idea and reality of “population” reside at the nexus of this question. Clarifying the substantive defining features of populations, including who and what structures the dynamic and emergent distributions of their characteristics and components, is thus crucial to both analyzing and altering causal processes. For public health, this means sharpening our thinking about how structured chances, structured by the political and economic relationships constituting the societal determinants of health ( Birn, Pillay, and Holtz 2009 ; Irwin et al. 2006 ; Krieger 1994 , 2011 ), generate the embodied phenotypes that are the people's health.
As should be evident, the challenges to developing critical population-informed thinking are not purely conceptual; they are also political, because these ideas necessarily engage with issues involving not only the distribution of people but also the distribution of power and property and the societal relationships that bind individuals and populations, for good and for bad ( Krieger 2011 ). Nearly two hundred years after Quetelet introduced his “l’homme moyen,” the countervailing call for routinely measuring and tracking population health inequities, and not just on-average population rates of health, is only now gaining traction globally (WHO 2008, 2011). This is coincident with the ever-accelerating aforementioned genomic quest for “personalized medicine” ( Davey Smith 2011 ), as well as the continued economic, social, political, and public health reverberations of the 2008 global economic crash ( Benatar, Gill, and Bakker 2011 ; Stiglitz 2010 ). In such a context, clarity regarding who and what populations are, and the making and meaning of their means, is vital to population sciences, population health, and the promotion of health equity.
Acknowledgments
No funding supported this work.
- Althuis MD, Dozier JM, Anderson WF, Devesa SS, Brinton LA. Global Trends in Breast Cancer Incidence and Mortality 1973–1999. International Journal of Epidemiology. 2005;34:405–12. doi: 10.1093/ije/dyh414. [ DOI ] [ PubMed ] [ Google Scholar ]
- Bateson P, Gluckman P. Plasticity and Robustness in Development and Evolution. International Journal of Epidemiology. 2012;41:219–23. doi: 10.1093/ije/dyr240. [ DOI ] [ PubMed ] [ Google Scholar ]
- Benatar SR, Gill S, Bakker I. Global Health and the Global Economic Crisis. American Journal of Public Health. 2011;101:646–53. doi: 10.2105/AJPH.2009.188458. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Biersack A, Greenberg JB. Reimagining Political Ecology. Durham, NC: Duke University Press; 2006. [ Google Scholar ]
- Birn AE, Pillay Y, Holtz TM. Textbook of International Health: Global Health in a Dynamic World. 3rd ed. New York: Oxford University Press; 2009. [ Google Scholar ]
- Braatne JH, Rood SB, Heillman PE. Life History, Ecology, and Conservation of Riparian Cottonwoods in North America. In: Stettler RF, Bradshaw HD Jr, Heilman PE, Hinckley TM, editors. Biology of Populus and Its Implications for Management and Conservation. Ottawa: National Research Council of Canada, NRC Research Press; 1996. pp. 57–85. [ Google Scholar ]
- Bray F, McCarron P, Parkin DM. The Changing Global Patterns of Female Breast Cancer Incidence and Mortality. Breast Cancer Research. 2004;6:229–39. doi: 10.1186/bcr932. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Brett KM, Madans JH. Difference in Use of Postmenopausal Hormone Replacement Therapy by Black and White Women. Menopause. 1997;4:66–70. [ Google Scholar ]
- Briggs H. Women's Cancers Reach Two Million. 2011. BBC News Health, September 14. Available at http://www.bbc.co.uk/news/health-14917284 (accessed June 17, 2012)
- Broadbent A. Inferring Causation in Epidemiology: Mechanisms, Black Boxes, and Contrasts. In: Illari PM, Russo F, Williamson J, editors. Causality in the Sciences. Oxford: Oxford University Press; 2011. pp. 45–69. [ Google Scholar ]
- Bud R. Oxford Dictionary of National Biography. Oxford: Oxford University Press; 2004. Hogben, Lancelot Thomas (1895–1975) Available at http://www.oxforddnb.com.ezp-prod1.hul.harvard.edu/view/article/31244?docPos=1 (accessed June 17, 2012) [ Google Scholar ]
- Burian RM, Zallen DT. Genes. In: Bowler PJ, Pickstone JV, editors. The Modern Biological and Earth Sciences. Cambridge: Cambridge University Press; 2009. Cambridge Histories Online. DOI: 10.1017/CHOL9780521572019.024 . [ Google Scholar ]
- Butler AHB. Obituary: Major Greenwood. Journal of the Royal Statistical Society: Series A (General) 1949;112:487–89. [ Google Scholar ]
- Carlson EA. The Unfit: A History of a Bad Idea. Cold Spring Harbor, NY: Cold Spring Harbor Press; 2001. [ Google Scholar ]
- Cartwright N. Predicting “It Will Work for Us”: (Way) beyond Statistics. In: Illari PM, Russo F, Williamson J, editors. Causality in the Sciences. Oxford: Oxford University Press; 2011. pp. 750–68. [ Google Scholar ]
- Carver T. Marx and Marxism. In: Porter TM, Ross D, editors. The Modern Social Sciences. Cambridge: Cambridge University Press; 2003. Cambridge Histories Online. DOI: 10.1017/CHOL9780521594424.013 . [ Google Scholar ]
- Chen H-T, Rossi PH. The Theory-Driven Approach to Validity. Evaluation and Program Planning. 1987;10:95–103. [ Google Scholar ]
- Clarke A, Agrò AF, Zheng Y, Tickle C, Jansson R, Kehrer-Sawatzki H, Cooper DN, Delves P, Battista J, Melino G, Perkel DJ, Hetherington AM, Bynum WF, Valpuesta JM, Harper D. Encyclopedia of Life Sciences. Chichester: Wiley; 2000. –2011. Available at http://www.els.net/WileyCDA/ (accessed September 6, 2011) [ Google Scholar ]
- Coggon DIW, Martyn CN. Time and Chance: The Stochastic Nature of Disease Causation. The Lancet. 2005;365:1434–37. doi: 10.1016/S0140-6736(05)66380-5. [ DOI ] [ PubMed ] [ Google Scholar ]
- Cole J. The Power of Large Numbers: Populations, Politics, and Gender in Nineteenth-Century France. Ithaca, NY: Cornell University Press; 2000. [ Google Scholar ]
- Cook TD. Generalization: Conceptions in the Social Sciences. In: Smelser NJ, Baltes PB, editors. International Encyclopedia of the Social & Behavioral Sciences. Oxford: Pergamon; 2001. pp. 6037–43. DOI: 10.1016/B0-08-043076-7/00698-7 . [ Google Scholar ]
- Cowan RS. Oxford Dictionary of National Biography. Oxford: Oxford University Press; 2004. Galton, Sir Francis (1822–1911) Available at http://www.oxforddnb.com.ezp-prod1.hul.harvard.edu/view/article/33315 (accessed June 17, 2012) [ Google Scholar ]
- Crosby RA, Salazar LF, DiClemente RJ, Lang DL. Balancing Rigor against the Inherent Limitations of Investigating Hard-to-Reach Populations. Health Education Research. 2010;25:1–5. doi: 10.1093/her/cyp062. [ DOI ] [ PubMed ] [ Google Scholar ]
- Crow JF. R.A. Fisher: A Centennial View. Genetics. 1990;124:204–11. doi: 10.1093/genetics/124.2.207. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Crow JF. Sewall Wright (1889–1988): A Biographical Memoir. Washington, DC: National Academy of Science; 1994. [ Google Scholar ]
- Daintith J, Martin E, editors. A Dictionary of Science. 5th ed. Oxford: Oxford University Press; 2005. [ Google Scholar ]
- Dale AI, Katz S. Arthur L. Bowley: A Pioneer in Modern Statistics and Economics. London: World Scientific Publishing; 2011. [ Google Scholar ]
- Daniel TM. Wade Hampton Frost: Pioneer Epidemiologist 1880–1938. Rochester, NY: University of Rochester Press; 2004. [ Google Scholar ]
- Darwin C. Origin of Species. Edison, NJ: Castle Books; 2004. (1859) [ Google Scholar ]
- Daston LJ. Rational Individuals versus Laws of Society: From Probability to Statistics. In: Krüger L, Daston LJ, Heidelberger M, editors. The Probabilistic Revolution. Vol. 1, Ideas in History. Cambridge, MA: MIT Press; 1987. pp. 295–304. [ Google Scholar ]
- Davenport CB. Heredity in Relation to Eugenics. New York: Henry Holt; 1911. [ Google Scholar ]
- Davey Smith G. Health Inequalities: Lifecourse Approaches. Bristol: Policy Press; 2003. [ Google Scholar ]
- Davey Smith G. Epidemiology, Epigenetics and the “Gloomy Prospect”: Embracing Randomness in Population Health Research and Practice. International Journal of Epidemiology. 2011;40:537–62. doi: 10.1093/ije/dyr117. [ DOI ] [ PubMed ] [ Google Scholar ]
- Davey Smith G. Epigenesis for Epidemiologists: Does Evo-Devo Have Implications for Population Health Research and Practice. International Journal of Epidemiology. 2012;41:236–47. doi: 10.1093/ije/dys016. [ DOI ] [ PubMed ] [ Google Scholar ]
- Davey Smith G, Morris J. A Conversation with Jerry Morris. Epidemiology. 2004;15:770–73. doi: 10.1097/01.ede.0000142155.20764.9d. [ DOI ] [ PubMed ] [ Google Scholar ]
- Davis K, Rowland D. Uninsured and Underserved: Inequities in Health Care in the United States. The Milbank Quarterly. 1983;61:149–76. [ PubMed ] [ Google Scholar ]
- Desrosières A. The Politics of Large Numbers: A History of Statistical Reasoning. Cambridge, MA: Harvard University Press; 1998. Trans. Camille Naish. [ Google Scholar ]
- Dominguez-Bello MG, Blaser MJ. The Human Microbiota as a Marker for Migrations of Individuals and Populations. Annual Review of Anthropology. 2011;40:451–74. [ Google Scholar ]
- Dunn BK, Agurs-Collins T, Browne D, Lubet R, Johnson KA. Health Disparities in Breast Cancer: Biology Meets Socioeconomic Status. Breast Cancer Research and Treatment. 2010;121:281–92. doi: 10.1007/s10549-010-0827-x. [ DOI ] [ PubMed ] [ Google Scholar ]
- Eldredge N. The Pattern of Evolution. New York: Freeman; 1999. [ Google Scholar ]
- Eldredge N. Darwin: Discovering the Tree of Life. New York: Norton; 2005. [ Google Scholar ]
- Eldredge N, Grene M. Interactions: The Biological Context of Social Systems. New York: Columbia University Press; 1992. [ Google Scholar ]
- Evans RG, Barer ML, Marmor TR. Why Are Some People Healthy and Others Not? The Determinants of Health of Populations. New York: De Gruyter; 1994. [ Google Scholar ]
- Falk R. The Gene—A Concept in Tension: A Critical Overview. In: Beurton PJ, Falk R, Rehinberger H-J, editors. The Concept of the Gene in Development and Evolution: Historical and Epistemological Perspectives. Cambridge: Cambridge University Press; 2000. pp. 317–49. [ Google Scholar ]
- Fee E. Disease and Discovery: A History of the Johns Hopkins School of Hygiene and Public Health, 1916–1939. Baltimore: Johns Hopkins University Press; 1987. [ Google Scholar ]
- Fergus C. Trees of New England: A Natural History. Guildford, CT: FalconGuide; 2005. [ Google Scholar ]
- Ferlay J, Forman D, Mathers CD, Bray F. Re: “Breast and Cervical Cancer in 187 Countries between 1980 and 2010”. The Lancet. 2012;379:1390–91. doi: 10.1016/S0140-6736(12)60595-9. [ DOI ] [ PubMed ] [ Google Scholar ]
- Foner E, editor. The New American History. Rev. and expanded ed. Philadelphia: Temple University Press; 1997. [ Google Scholar ]
- Forouzanafar MH, Foreman KJ, Delossantos AM, Lozano R, Lopez AD, Murray CJ, Naghanvi M. Breast and Cervical Cancer in 187 Countries between 1980 and 2010: A Systematic Analysis. The Lancet. 2011;378:1461–84. doi: 10.1016/S0140-6736(11)61351-2. [ DOI ] [ PubMed ] [ Google Scholar ]
- Fox SE, Levitt P, Nelson CA., III How the Timing and Quality of Early Experiences Influence the Development of Brain Architecture. Child Development. 2010;81:28–40. doi: 10.1111/j.1467-8624.2009.01380.x. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Friedman-Koss D, Crespo CJ, Bellantoni MF, Andersen RE. The Relationship of Race/Ethnicity and Social Class to Hormone Replacement Therapy: Results from the Third National Health and Nutrition Examination Survey 1988–1994. Menopause. 2002;9:264–72. doi: 10.1097/00042192-200207000-00007. [ DOI ] [ PubMed ] [ Google Scholar ]
- Frost C, Appel H, Carlson J, De Moraes CM, Mescher M, Schultz JC. Within-Plant Signaling by Volatiles Overcomes Vascular Constraints on Systemic Signaling and Primes Responses against Herbivores. Ecology Letters. 2007;10:490–98. doi: 10.1111/j.1461-0248.2007.01043.x. [ DOI ] [ PubMed ] [ Google Scholar ]
- Frost WH. In: Epidemiology. Maxcy KF, editor. New York: Commonwealth Fund; 1941. pp. 439–52. (1927) In Papers of Wade Hampton Frost, M.D. [ Google Scholar ]
- Frost WH. 1976. Some Conceptions of Epidemics in General. American Journal of Epidemiology. 1928;103:141–51. doi: 10.1093/oxfordjournals.aje.a112212. [ DOI ] [ PubMed ] [ Google Scholar ]
- Galton F. Natural Inheritance. London: Macmillan; 1889. [ Google Scholar ]
- Galton F. Eugenics: Its Definition, Scope, and Aims. Nature. 1904;70:82. [ Google Scholar ]
- Gaziano JM. The Evolution of Population Science: Advent of the Mega Cohort. JAMA. 2010;304:2288–89. doi: 10.1001/jama.2010.1691. [ DOI ] [ PubMed ] [ Google Scholar ]
- Gibson JJ. The Ecological Approach to Visual Perception. Hillsdale, NJ: Erlbaum; 1986. [ Google Scholar ]
- Giddens A, Held D, editors. Classes, Power, and Conflict: Classical and Contemporary Debates. Berkeley: University of California Press; 1982. [ Google Scholar ]
- Gilbert SF, Epel D. Ecological Developmental Biology: Integrating Epigenetics, Medicine, and Evolution. Sunderland, MA: Sinaeur Associates; 2009. [ Google Scholar ]
- GLOBOCAN. 2012. Data Sources and Methods. International Agency for Research on Cancer, World Health Organization. Available at http://globocan.iarc.fr/ (accessed June 17, 2012)
- Greenhalgh S. The Social Construction of Population Science: An Intellectual, Institutional, and Political History of Twentieth-Century Demography. Comparative Studies Society History. 1996;38:26–66. [ Google Scholar ]
- Greenwood M. Epidemics and Crowd Diseases: An Introduction to the Study of Epidemiology. London: Williams & Norgate; 1935. [ Google Scholar ]
- Grene M, Depew D. The Philosophy of Biology. Cambridge: Cambridge University Press; 2004. [ Google Scholar ]
- Hacking I. The Emergence of Probability. Cambridge: Cambridge University Press; 1975. [ Google Scholar ]
- Hacking I. The Taming of Chance. Cambridge: Cambridge University Press; 1990. [ Google Scholar ]
- Hankins FH. Adolphe Quetelet as Statistician. New York: Arno Press; 1968. [ Google Scholar ]
- Harraway DJ. When Species Meet. Minneapolis: University of Minnesota Press; 2008. [ Google Scholar ]
- Harré R. Individual/Society: History of the Concept. In: Smelser NJ, Baltes PB, editors. International Encyclopedia of the Social & Behavioral Sciences. Oxford: Pergamon; 2001. pp. 7306–10. DOI: 10.1016/B0-08-043076-7/00125-X . [ Google Scholar ]
- Harvey D. Justice, Nature, and the Geography of Difference. Cambridge, MA: Blackwell; 1996. [ Google Scholar ]
- Heesterbeek H. The Law of Mass-Action in Epidemiology: A Historical Perspective. In: Cuddington K, Beisner BE, editors. Ecological Paradigms Lost: Routes of Theory Change. Burlington, MA: Elsevier Academic Press; 2005. pp. 81–106. [ Google Scholar ]
- Heilbron J, Magnusson L, Wittrock B, editors. The Rise of the Social Sciences and the Formation of Modernity: Conceptual Change in Context, 1750–1850. Dordrecht: Kluwer Academic Publishers; 1998. [ Google Scholar ]
- Hey J. Regarding the Confusion between the Population Concept and Mayr's “Population Thinking.”. Quarterly Review of Biology. 2011;86:253–64. doi: 10.1086/662455. [ DOI ] [ PubMed ] [ Google Scholar ]
- Hodge J. Evolution. In: Bowler PJ, Pickstone JV, editors. The Modern Biological and Earth Sciences. Cambridge: Cambridge University Press; 2009. Cambridge Histories Online. DOI: 10.1017/CHOL9780521572019.015 . [ Google Scholar ]
- Hogben L. Nature and Nurture. London: Williams & Norgate; 1933. [ Google Scholar ]
- Hogben L. Major Greenwood: 1880–1949. Obituary Notices of Fellows of the Royal Society. 1950;7:138–54. [ Google Scholar ]
- IHME (Institute for Health Metrics and Evaluation) The Challenge Ahead: Progress and Setbacks in Breast and Cervical Cancer. Seattle: 2011. [ Google Scholar ]
- Illari PM, Russo F, Williamson J. Why Look at Causality in the Sciences? A Manifesto. In: Illari PM, Russo F, Williamson J, editors. Causality in the Sciences. Oxford: Oxford University Press; 2011. pp. 3–22. [ Google Scholar ]
- Irwin A, Valentine N, Brown C, Loewenson R, Solar O, Brown H, Koller T, Vega J. The Commission on the Social Determinants of Health: Tackling the Social Roots of Health Inequities. PLoS Medicine. 2006;3(6):e106. doi: 10.1371/journal.pmed.0030106. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Issac J. The Human Sciences in Cold War America. Historical Journal. 2007;50:725–46. [ Google Scholar ]
- Jansson S, Douglas CJ. Populus: A Model System for Plant Biology. Annual Review of Plant Biology. 2007;58:435–458. doi: 10.1146/annurev.arplant.58.032806.103956. [ DOI ] [ PubMed ] [ Google Scholar ]
- Jaslow R. CBS News. 2011. Breast, Cervical Cancer Rates Rising around World: Why? September 15, 2011. Available at http://www.cbsnews.com/8301-504763_162-20106719-10391704.html (accessed June 17, 2012) [ Google Scholar ]
- Keller EF. The Century of the Gene. Cambridge, MA: Harvard University Press; 2000. [ Google Scholar ]
- Keller EF. The Mirage of a Space between Nature and Nurture. Durham, NC: Duke University Press; 2010. [ Google Scholar ]
- Kermack WO, McKendrick AG. Contributions to the Mathematical Theory of Epidemics, Part I. Proceedings of the Royal Society Series A. 1927;115:700–721. [ Google Scholar ]
- Kevels D. In the Name of Eugenics: Genetics and the Uses of Human Heredity. New York: Knopf; 1985. [ Google Scholar ]
- Kincaid H. Causal Modeling, Mechanisms, and Probability in Epidemiology. In: Illari PM, Russo F, Williamson J, editors. Causality in the Sciences. Oxford: Oxford University Press; 2011. pp. 70–90. [ Google Scholar ]
- Klassen AC, Smith KC. The Enduring and Evolving Relationship between Social Class and Breast Cancer Burden: A Review of the Literature. Cancer Epidemiology. 2011;35:217–34. doi: 10.1016/j.canep.2011.02.009. [ DOI ] [ PubMed ] [ Google Scholar ]
- Kolata G. New York Times. 2006. Reversing Trend, Big Drop Is Seen in Breast Cancer. December 15. Available at http://www.nytimes.com/2006/12/15/health/15breast.html?pagewanted=all (accessed June 17, 2012) [ Google Scholar ]
- Kolata G. New York Times. 2007. Sharp Drop in Rates of Breast Cancer Holds. April 19. Available at http://query.nytimes.com/gst/fullpage.html?res=9a03e6d91e3ff93aa25757c0a9619c8b63 (accessed June 17, 2012) [ Google Scholar ]
- Krieger N. Epidemiology and the Web of Causation: Has Anyone Seen the Spider. Social Science & Medicine. 1994;39:887–903. doi: 10.1016/0277-9536(94)90202-x. [ DOI ] [ PubMed ] [ Google Scholar ]
- Krieger N. Epidemiology and Social Sciences: Towards a Critical Reengagement in the 21st Century. Epidemiology Review. 2000;11:155–63. doi: 10.1093/oxfordjournals.epirev.a018014. [ DOI ] [ PubMed ] [ Google Scholar ]
- Krieger N. Theories for Social Epidemiology in the 21st Century: An Ecosocial Perspective. International Journal of Epidemiology. 2001;30:668–77. doi: 10.1093/ije/30.4.668. [ DOI ] [ PubMed ] [ Google Scholar ]
- Krieger N. Breast Cancer: A Disease of Affluence, Poverty, or Both?—The Case of African American Women. American Journal of Public Health. 2002;92:611–13. doi: 10.2105/ajph.92.4.611. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Krieger N. Embodiment: A Conceptual Glossary for Epidemiology. Journal of Epidemiology & Community Health. 2005;59:350–55. doi: 10.1136/jech.2004.024562. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Krieger N. Ways of Asking and Ways of Living: Reflections on the 50th Anniversary of Morris’ Ever-Useful Uses of Epidemiology. International Journal of Epidemiology. 2007a;36:1173–80. doi: 10.1093/ije/dym228. [ DOI ] [ PubMed ] [ Google Scholar ]
- Krieger N. Why Epidemiologists Cannot Afford to Ignore Poverty. Epidemiology. 2007b;18:658–63. doi: 10.1097/EDE.0b013e318156bfcd. [ DOI ] [ PubMed ] [ Google Scholar ]
- Krieger N. Hormone Therapy and the Rise and Perhaps Fall of US Breast Cancer Incidence Rates: Critical Reflections. International Journal of Epidemiology. 2008;37:627–37. doi: 10.1093/ije/dyn055. [ DOI ] [ PubMed ] [ Google Scholar ]
- Krieger N. Epidemiology and the People's Health: Theory and Context. New York: Oxford University Press; 2011. [ Google Scholar ]
- Krieger N, Bassett M, Gomez S. Re: “Breast and Cervical Cancer in 187 Countries between 1980 and 2010.”. The Lancet. 2012;379:1391–92. doi: 10.1016/S0140-6736(12)60596-0. [ DOI ] [ PubMed ] [ Google Scholar ]
- Krieger N, Chen JT, Waterman PD. Decline in US Breast Cancer Rates after the Women's Health Initiative: Socioeconomic and Racial/Ethnic Differentials. American Journal of Public Health. 2010;100:S132–S139. doi: 10.2105/AJPH.2009.181628. erratum, 972. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Krieger N, Chen JT, Waterman PD. Temporal Trends in the Black/White Breast Cancer Case Ratio for Estrogen Receptor Status: Disparities Are Historically Contingent, Not Innate. Cancer Causes and Control. 2011;22:511–14. doi: 10.1007/s10552-010-9710-7. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Krieger N, Davey Smith G. Bodies Count & Body Counts: Social Epidemiology & Embodying Inequality. Epidemiology Review. 2004;26:92–103. doi: 10.1093/epirev/mxh009. [ DOI ] [ PubMed ] [ Google Scholar ]
- Krieger N, Fee E. Measuring Social Inequalities in Health in the United States: An Historical Review, 1900–1950. International Journal of Health Services. 1996;26:391–418. doi: 10.2190/B3AH-Q5KE-VBGF-NC74. [ DOI ] [ PubMed ] [ Google Scholar ]
- Krieger N, Williams D, Moss N. Measuring Social Class in US Public Health Research: Concepts, Methodologies and Guidelines. Annual Review of Public Health. 1997;18:341–78. doi: 10.1146/annurev.publhealth.18.1.341. [ DOI ] [ PubMed ] [ Google Scholar ]
- Kuhlmann M. Mechanisms in Dynamically Complex Systems. In: Illari PM, Russo F, Williamson J, editors. Causality in the Sciences. Oxford: Oxford University Press; 2011. pp. 880–906. [ Google Scholar ]
- Kukuall WA, Ganguli M. Generalizability: The Trees, the Forest, and the Low-Hanging Fruit. Neurology. 2012;78:1886–91. doi: 10.1212/WNL.0b013e318258f812. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Kunitz SJ. The Health of Populations: General Theories and Particular Realities. New York: Oxford University Press; 2007. [ Google Scholar ]
- Kuzawa C. Why Evolution Needs Development, and Medicine Needs Evolution. International Journal of Epidemiology. 2012;41:223–29. doi: 10.1093/ije/dys005. [ DOI ] [ PubMed ] [ Google Scholar ]
- Lane-Claypon JE. A Further Report on Cancer of the Breast with Special Reference to Its Associated Antecedent Conditions. Reports on Public Health and Medical Subjects no. 32. London: HMSO; 1926. [ Google Scholar ]
- Lewontin R. The Triple Helix: Gene, Organism, and Environment. Cambridge, MA: Harvard University Press; 2000. [ Google Scholar ]
- Lilienfeld AM, editor. Times, Places, and Persons: Aspects of the History of Epidemiology. Baltimore: Johns Hopkins University Press; 1980. [ Google Scholar ]
- Limpert E, Stahel WA, Abbt M. Log-Normal Distributions across the Sciences: Keys and Clues. BioSci. 2001;51:341–52. [ Google Scholar ]
- Mackenzie D. Statistics in Britain, 1865–1930: The Social Construction of Scientific Knowledge. Edinburgh: Edinburgh University Press; 1982. [ Google Scholar ]
- Martin J, Harré R. Metaphor in Science. In: Miall DS, editor. Metaphor: Problems and Perspectives. Sussex, NJ: Harvester Press; 1982. pp. 89–105. [ Google Scholar ]
- Marx K. In: Theses on Feuerbach. Dietz JHW, editor. Stuttgart: 1845. 1888. First published, in an edited version, as an appendix to Engels F. Ludwig Feuerbach und der Ausgang der klassischen deutschen Philosophie. Mit Anghard: Karl Marx über Feuerbach von Jarhe 1845. Available at http://www.marxists.org/archive/marx/works/1845/theses/index.htm (2002 trans. by Cyril Smith) (accessed June 17, 2012) [ Google Scholar ]
- Mayr E. Towards a New Philosophy of Biology: Observations of an Evolutionist. Cambridge, MA: Harvard University Press; 1988. [ Google Scholar ]
- Mendelsohn JA. From Eradication to Equilibrium: How Epidemics Became Complex after World War I. In: Lawrence C, Weisz G, editors. Greater Than the Parts: Holism in Biomedicine, 1920–1950. New York: Oxford University Press; 1998. pp. 303–31. [ Google Scholar ]
- Mitchell M. Complexity: A Guided Tour. Oxford: Oxford University Press; 2009. [ Google Scholar ]
- Morange M. The Misunderstood Gene. Cambridge, MA: Harvard University Press; 2001. [ Google Scholar ]
- Morris JN. Uses of Epidemiology. Edinburgh: E. & S. Livingston; 1957. [ Google Scholar ]
- Mountain JL. Human Evolutionary Genetics. In: Smelser NJ, Baltes PB, editors. International Encyclopedia of the Social & Behavioral Sciences. Oxford: Pergamon, Oxford; 2001. pp. 6984–91. DOI: 10.1016/B0-08-043076-7/03088-6 . [ Google Scholar ]
- Nash K, Scott A, editors. The Blackwell Companion to Political Sociology. Malden, MA: Blackwell; 2001. [ Google Scholar ]
- OED (Oxford English Dictionary) online. 2010. Draft revision June. Available at http://dictionary.oed.com.ezp-prod1.hul.harvard.edu/ (accessed June 17, 2012)
- Parkin DM, Fernández LMG. Use of Statistics to Assess the Global Burden of Breast Cancer. Breast Journal. 2006;12(suppl. 1):S70– S80. doi: 10.1111/j.1075-122X.2006.00205.x. [ DOI ] [ PubMed ] [ Google Scholar ]
- Pearce N. Epidemiology as a Population Science. International Journal of Epidemiology. 1999;28:S1015–S18. doi: 10.1093/oxfordjournals.ije.a019904. [ DOI ] [ PubMed ] [ Google Scholar ]
- Pflughoeft KJ, Versalovic J. Human Microbiome in Health and Disease. Annual Review of Pathology: Mechanisms of Disease. 2012;7:99–122. doi: 10.1146/annurev-pathol-011811-132421. [ DOI ] [ PubMed ] [ Google Scholar ]
- Piermsa T, van Gils JA. The Flexible Phenotype: A Body-Centered Integration of Ecology, Physiology, and Behavior. New York: Oxford University Press; 2011. [ Google Scholar ]
- Pizzi C, De Stavola B, Merletti F, Bellocco R, dos Santos Silva I, Pearce N, Richiardi L. Sample Selection and Validity of Exposure-Disease Association Estimates in Cohort Studies. Journal of Epidemiology & Community Health. 2011;65:407–11. doi: 10.1136/jech.2009.107185. [ DOI ] [ PubMed ] [ Google Scholar ]
- Porta M, editor. A Dictionary of Epidemiology. 5th ed. Oxford: Oxford University Press; 2008. [ Google Scholar ]
- Porter TM. A Statistical Survey of Gases: Maxwell's Social Physics. Historical Studies in the Physical Sciences. 1981;12:77–116. [ Google Scholar ]
- Porter TM. The Rise of Statistical Thinking, 1820–1900. Princeton, NJ: Princeton University Press; 1986. [ Google Scholar ]
- Porter TM. Trust in Numbers: The Pursuit of Objectivity in Science and Public Life. Princeton, NJ: Princeton University Press; 1995. [ DOI ] [ PubMed ] [ Google Scholar ]
- Porter TM. Statistics and Physical Theories. In: Nye MJ, editor. The Modern Physical and Mathematical Sciences. Cambridge: Cambridge University Press; 2002. Cambridge Histories Online. DOI: 10.1017/CHOL9780521571999.027 . [ Google Scholar ]
- Porter TM. Statistics and Statistical Methods. In: Porter TM, Ross D, editors. The Modern Social Sciences. Cambridge: Cambridge University Press; 2003. Cambridge Histories Online. DOI: 10.1017/CHOL9780521594424.015 . [ Google Scholar ]
- Press DJ, Pharoah P. Risk Factors for Breast Cancer: A Reanalysis of Two Case-Control Studies from 1926 and 1931. Epidemiology. 2010;21:566–72. doi: 10.1097/EDE.0b013e3181e08eb3. [ DOI ] [ PubMed ] [ Google Scholar ]
- Quetelet A. In: Sur l’homme et le development des ses facultés, ou essai de physique sociale. Knox R, translator. 1835. Paris. For a translation, see Quetelet, A. (1842) 1968. A Treatise on Man and the Development of His Faculties. Reprint, New York: Burt Franklin. [ Google Scholar ]
- Quetelet A. Recherches statistiques. Brussels: M. Hayez (Imprimeur de la Commission centrale de statistique); 1844. [ Google Scholar ]
- Ramsden E. Carving Up Population Science: Eugenics, Demography and the Controversy over the “Biological Law” of Population Growth. Social Studies of Science. 2002;32:857–99. [ Google Scholar ]
- Ravdin PM, Cronin KA, Howlader N, Berg CD, Chlebowski RT, Feuer EJ, Edwards BK, Berry DA. The Decrease in Breast-Cancer Incidence in 2003 in the United States. New England Journal of Medicine. 2007;356:1670–74. doi: 10.1056/NEJMsr070105. [ DOI ] [ PubMed ] [ Google Scholar ]
- Ravdin PM, Cronin KA, Howlader N, Chlebowski RT, Berry DA. A Sharp Decrease in Breast Cancer Incidence in the United States in 2003. Breast Cancer Research and Treatment. 2006;100(suppl) S2 (abstract) [ Google Scholar ]
- Relton CL, Davey Smith G. Is Epidemiology Ready for Epigenetics? International Journal of Epidemiology. 2012;41:5–9. doi: 10.1093/ije/dys006. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Richards RA. Encyclopedia of Life Sciences. New York: Wiley; 2001. Species Problem—A Philosophical Analysis. (online 2007). DOI: 10.1002/9780470015902.a0003456 . [ Google Scholar ]
- Rose D, Pevalin DJ, editors. A Researcher's Guide to the National Statistics Socio-economic Classification. London: Sage; 2003. [ DOI ] [ PubMed ] [ Google Scholar ]
- Rose GA. Sick Individuals and Sick Populations. International Journal of Epidemiology. 1985;14:32–38. doi: 10.1093/ije/14.1.32. [ DOI ] [ PubMed ] [ Google Scholar ]
- Rose GA. The Strategy of Preventive Medicine. Oxford: Oxford University Press; 1992. [ Google Scholar ]
- Rose GA. Rose's Strategy of Preventive Medicine: The Complete Original Text, with a Commentary by Kay-Tee Khaw and Michael Marmot. Oxford: Oxford University Press; 2008. [ Google Scholar ]
- Rosen G. A History of Public Health. Baltimore: Johns Hopkins University Press; 1993. (1958) Expanded ed. Introduction by E. Fee; biographical essay and new bibliography by E.T. Morman. [ Google Scholar ]
- Ross D. Changing Contours of the Social Science Disciplines. In: Porter TM, Ross D, editors. The Modern Social Sciences. Cambridge: Cambridge University Press; 2003. pp. 275–305. [ Google Scholar ]
- Rossouw JE, Anderson GL, Prentice RL, LaCroix AZ, Kooperberg C, Stefanick ML, Jackson RD, Beresford SA, Howard BV, Johnson KC, Kotchen JM, Ockene J, Writing Group for the Women's Health Initiative Investigators Risk and Benefits of Estrogen plus Progestin in Healthy Postmenopausal Women: Principal Results from the Women's Health Initiative Randomized Controlled Trial. JAMA. 2002;288:321–33. doi: 10.1001/jama.288.3.321. [ DOI ] [ PubMed ] [ Google Scholar ]
- Rothman KJ, Greenland S, Lash TL. Modern Epidemiology. 3rd ed. Philadelphia: Lippincott Williams & Wilkins; 2008. [ Google Scholar ]
- Sarkar S. Lancelot Hogben, 1895–1975. Genetics. 1996;142:655–60. [ Google Scholar ]
- Schank JC, Twardy C. Mathematical Models. In: Bowler PJ, Pickstone JV, editors. The Modern Biological and Earth Sciences. Cambridge: Cambridge University Press; 2009. Cambridge Histories Online. DOI: 10.1017/CHOL9780521572019.023 . [ Google Scholar ]
- Schlesselman JJ, Stadel BV. Exposure Opportunity in Epidemiologic Studies. American Journal of Epidemiology. 1987;125:174–78. doi: 10.1093/oxfordjournals.aje.a114517. [ DOI ] [ PubMed ] [ Google Scholar ]
- Scott J, Marshall G, editors. A Dictionary of Sociology. 3rd ed. Oxford: Oxford University Press; 2005. [ Google Scholar ]
- Shaghaghi A, Bhopal RJ, Sheik A. Approaches to Recruiting “Hard-to-Reach” Populations in Research: Review of the Literature. Health Promotion Perspectives. 2011;1(2):1–9. doi: 10.5681/hpp.2011.009. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Smith GD. The Uses of “Uses of Epidemiology.”. International Journal of Epidemiology. 2001;30:1146–55. doi: 10.1093/ije/30.5.1146. [ DOI ] [ PubMed ] [ Google Scholar ]
- Smylie J, Lofters A, Firestone M, O’Campo P. Population-Based Data and Community Empowerment. In: O’Campo P, Dunn JR, editors. Rethinking Social Epidemiology: Towards a Science of Change. Dordrecht: Springer Science+Business Media B.V; 2012. pp. 68–92. [ Google Scholar ]
- Stanley D, Phelps AE, Banaji MR. The Neural Basis of Implicit Attitudes. Current Directions in Psychological Science. 2008;17:165–70. [ Google Scholar ]
- Steinman E. Sovereigns and Citizens? The Contested Status of American Indian Tribal Nations and Their Members. Citizenship Studies. 2011;15:57–74. [ Google Scholar ]
- Stigler SM. The History of Statistics: The Measurement of Uncertainty before 1900. Cambridge, MA: Belknap Press /Harvard University Press; 1986. [ Google Scholar ]
- Stigler SM. Regression towards the Mean, Historically Considered. Statistical Methods in Medical Research. 1997;6:103–14. doi: 10.1177/096228029700600202. [ DOI ] [ PubMed ] [ Google Scholar ]
- Stigler SM. The Average Man Is 168 Years Old. In: Stigler SM, editor. Statistics on the Table: The History of Statistical Concepts and Methods. Cambridge, MA: Harvard University Press; 2002. pp. 51–65. [ Google Scholar ]
- Stiglitz J. Freefall: America, Free Markets, and the Sinking World Economy. New York: Norton; 2010. [ Google Scholar ]
- Strevens M. Bigger Than Chaos: Understanding Complexity through Probability. Cambridge, MA: Harvard University Press; 2003. [ Google Scholar ]
- Susser M, Stein Z. Eras in Epidemiology: The Evolution of Ideas. New York: Oxford University Press; 2009. [ Google Scholar ]
- Svensson P-G. Special Issue: Health Inequities in Europe. Social Science & Medicine. 1990;31:225–27. doi: 10.1016/0277-9536(90)90268-w. [ DOI ] [ PubMed ] [ Google Scholar ]
- Sydenstricker E. Health and Environment. New York: McGraw-Hill; 1933. [ Google Scholar ]
- Tabery J. R.A. Fisher, Lancelot Hogben, and the Origin(s) of Genotype-Environment Interaction. Journal of the History of Biology. 2008;41:717–61. doi: 10.1007/s10739-008-9155-y. [ DOI ] [ PubMed ] [ Google Scholar ]
- Turner JH. A New Approach for Theoretically Integrating Micro and Macro Analyses. In: Calhoun C, Rojek C, Turner B, editors. The Sage Handbook of Sociology. Thousand Oaks, CA: Sage; 2005. pp. 405–22. [ Google Scholar ]
- U.S. Citizenship and Immigration Services. 2012. Citizenship. Available at http://www.uscis.gov/portal/site/uscis/ (accessed June 17, 2012)
- Vona-Davis L, Rose DP. The Influence of Socioeconomic Disparities on Breast Cancer Tumor Biology and Prognosis: A Review. Journal of Women's Health. 2009;18:883–93. doi: 10.1089/jwh.2008.1127. [ DOI ] [ PubMed ] [ Google Scholar ]
- Wainwright JM. A Comparison of Conditions Associated with Breast Cancer in Great Britain and America. American Journal of Cancer. 1931;15:2610–45. [ Google Scholar ]
- Wallace TA, Martin DN, Ambs S. Interactions among Genes, Tumor Biology and the Environment in Cancer Health Disparities: Examining the Evidence on a National and Global Scale. Carcinogenesis. 2011;32:1107–21. doi: 10.1093/carcin/bgr066. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Walter J, Ley R. The Human Gut Microbiome: Ecology and Recent Evolutionary Changes. Annual Review of Microbiology. 2011;65:411–29. doi: 10.1146/annurev-micro-090110-102830. [ DOI ] [ PubMed ] [ Google Scholar ]
- Weiss KM, Long JC. Non-Darwinian Estimation: My Ancestors, My Genes’ Ancestors. Genome Research. 2009;19:703–10. doi: 10.1101/gr.076539.108. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Werskey G. In: The Visible College: A Collective Biography of British Scientists and Socialists of the 1930s. Young RM, editor. London: Free Association Books; 1988. Foreword by. [ Google Scholar ]
- West-Eberhard MT. Developmental Plasticity and Evolution. New York: Oxford University Press; 2003. [ Google Scholar ]
- Whitehead M. The Concepts and Principles of Equity and Health. International Journal of Health Services. 1992;22:429–45. doi: 10.2190/986L-LHQ6-2VTE-YRRN. [ DOI ] [ PubMed ] [ Google Scholar ]
- WHO (World Health Organization) Closing the Gap in a Generation: Health Equity through Action on the Social Determinants of Health. 2008. Commission on the Social Determinants of Health—Final Report. Geneva. Available at http://www.who.int/social_determinants/thecommission/finalreport/en/index.html (accessed June 17, 2012) [ DOI ] [ PubMed ] [ Google Scholar ]
- WHO (World Health Organization) 2011. Rio Political Declaration on Social Determinants of Health. Rio de Janeiro, October 21. Available at http://www.who.int/sdhconference/declaration/en/index.html (accessed June 17, 2012)
- Wiehl DG. Edgar Sydenstricker: A Memoir. In: Kasius RV, editor. The Challenge of the Facts: Selected Public Health Papers of Edgar Sydenstricker. New York: Prodist, for the Milbank Memorial Fund; 1974. pp. 1–17. [ Google Scholar ]
- Williams R. Keywords: A Vocabulary of Culture and Society. Rev. ed. New York: Oxford University Press; 1985. [ Google Scholar ]
- Wimmer A, Schiller NG. Methodological Nationalism and Beyond: Nation-State, Migration, and the Social Sciences. Global Networks. 2002;4:301–34. [ Google Scholar ]
- Winkelstein W., Jr . Oxford Dictionary of National Biography. Oxford: Oxford University Press; 2004. Claypon, Janet Elizabeth Lane- [married name Janet Elizabeth Forber, Lady Forber] (1877–1967) Available at http://www.oxforddnb.com.ezp-prod1.hul.harvard.edu/view/article/61714 (accessed June 17, 2012) [ Google Scholar ]
- Winslow C-EA, Smillie WG, Doull JA, Gordon JE. In: The History of American Epidemiology. Top FH, editor. Mosby; 1952. Sponsored by the Epidemiology Section, American Public Health Association. St. Louis. [ Google Scholar ]
- Wright EO, editor. Approaches to Class Analysis. Cambridge: Cambridge University Press; 2005. [ Google Scholar ]
- Wright S. The Relative Importance of Heredity and Environment in Determining the Pie-Bald Pattern of Guinea-Pigs. 1920;6:320–32. doi: 10.1073/pnas.6.6.320. Proceedings of the National Academy of Sciences. [ DOI ] [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Yeo EJ. Social Surveys in the Eighteenth and Nineteenth Centuries. In: Porter TM, Ross D, editors. The Modern Social Sciences. Cambridge: Cambridge University Press; 2003. Cambridge Histories Online. DOI: 10.1017/CHOL9780521594424.007 . [ Google Scholar ]
- Young TK. Population Health: Concepts and Methods. 2nd ed. New York: Oxford University Press; 2005. [ Google Scholar ]
- Zbuk K, Anand SS. Declining Incidence of Breast Cancer after Decreased Use of Hormone-Replacement Therapy: Magnitude and Time Lags in Different Countries. Journal of Epidemiology & Community Health. 2012;66:1–7. doi: 10.1136/jech.2008.083774. [ DOI ] [ PubMed ] [ Google Scholar ]
- Ziman J. Real Science: What It Is and What It Means. Cambridge: Cambridge University Press; 2000. [ Google Scholar ]
- Zinn H. A People's History of the United States: 1492–Present. New York: HarperCollins; 2003. [ Google Scholar ]
- View on publisher site
- PDF (862.7 KB)
- Collections
Similar articles
Cited by other articles, links to ncbi databases.
- Download .nbib .nbib
- Format: AMA APA MLA NLM
Add to Collections
IMAGES
VIDEO
COMMENTS
Total: 2) Research population and sample serve as the cornerstones of any scientific inquiry. They hold the power to unlock the mysteries hidden within data. Understanding the dynamics between the research population and sample is crucial for researchers. It ensures the validity, reliability, and generalizability of their findings.
A population is a complete set of people with specified characteristics, while a sample is a subset of the population. 1 In general, most people think of the defining characteristic of a population in terms of geographic location. However, in research, other characteristics will define a population.
Email:[email protected]. Abstract: This paper thoroughly explores the foundational principles governing population. and target population concepts within research methodology. It ...
The first step in addressing the population in research is to clearly define the target population. This involves specifying the characteristics of the larger group to which the study's findings will be generalized. The target population should be explicitly defined in terms of relevant factors such as demographic characteristics, geographic ...
The sampling frame intersects the target population. The sam-ple and sampling frame described extends outside of the target population and population of interest as occa-sionally the sampling frame may include individuals not qualified for the study. Figure 1. The relationship between populations within research.
reference population. Share button. Updated on 04/19/2018. a subset of a target population that serves as a standard against which research findings are evaluated. For example, consider an investigator examining the effectiveness of eating disorder prevention programs at 4-year colleges and universities in the United States. In such a situation ...
A population is the entire group that you want to draw conclusions about.. A sample is the specific group that you will collect data from. The size of the sample is always less than the total size of the population. In research, a population doesn't always refer to people. It can mean a group containing elements of anything you want to study, such as objects, events, organizations, countries ...
In evaluating the study population selected, an important question is whether the population is appropriate to answer the research question. In clinical studies evaluating a treatment/intervention, investigators should also ask whether the study population selected is the group most likely to benefit (understanding there may be instances where another population has already been evaluated).
A population is a complete set of people with a specialized set of characteristics, and a sample is a subset of the population. The usual criteria we use in defining population are geographic, for example, "the population of Uttar Pradesh". In medical research, the criteria for population may be clinical, demographic and time related.
The essential topics related to the selection of participants for a health researchare: 1) whether to work with samples or include the whole reference population inthe study (census); 2) the sample basis; 3) the sampling process and 4) thepotential effects nonrespondents might have on study results. We will refer to eachof these aspects with ...
Study population is a subset of the target population from which the sample is actually selected. It is broader than the concept sample frame.It may be appropriate to say that sample frame is an operationalized form of study population. For example, suppose that a study is going to conduct a survey of high school students on their social well-being. ...
The defined population then will become the basis for applying the research results to other relevant populations. Clearly defining a study population early in the research process also helps assure the overall validity of the study results. Many research reports fail to define or describe a study population adequately.
interesting, it is only interesting in terms of being a guide to further research.3 And that is the big deal about populations in research. If our target population is not adequately described, readers/clinicians really have no frame of reference to evaluate the generalizability of our study. Not only do we as researchers need to sufficiently ...
design, population of interest, study setting, recruit ment, and sampling. Study Design. The study design is the use of e vidence-based. procedures, protocols, and guidelines that provide the ...
Abstract. This paper deals with the concept of Population and Sample in research, especially in educational and psychological researches and the researches carried out in the field of Sociology ...
reference collection that for 20 years was the basis of most anthropological and palaeodemographic studies in the French-speaking research community (Box 4.1). By convention,we shall use the term "Masset reference collection"for the setof individuals formed by the combination of these two collections. These are raw data
1. The source population in your example is somewhat ambiguous - though a source population for any given study is often somewhat hard to define. Generally speaking, the source population is the population from which your study subjects are drawn. In your example, that would be the 100,000 screened individuals under a specific assumption.
A population is the entire group that you want to draw conclusions about.. A sample is the specific group that you will collect data from. The size of the sample is always less than the total size of the population. In research, a population doesn't always refer to people. It can mean a group containing elements of anything you want to study, such as objects, events, organisations, countries ...
A research population is generally a large collection of individuals or objects that is the main focus of a scientific query. It is for the benefit of the population that researches are done. However, due to the large sizes of populations, researchers often cannot test every individual in the population because it is too expensive and time ...
The study population is the subset of the population with the condition or characteristics of interest defined by the eligibility criteria. The group of participants actually studied in the trial, which constitutes the trial participants, is selected from the study population. (See Fig. 4.1). There are two main types of exclusions.
Sample size calculations require assumptions about expected means and standard deviations, or event risks, in different groups; or, upon expected effect sizes. For example, a study may be powered to detect an effect size of 0.5; or a response rate of 60% with drug vs. 40% with placebo. [1] When no guesstimates or expectations are possible ...
In research, a population is the entire group that you want to draw conclusions about, while a sample is the smaller group of individuals you'll actually collect data from. Defining the population. A population can be made up of anything you want to study—plants, animals, organizations, texts, countries, etc. In the social sciences, it most ...
Methods. In this article, I review the current conventional definitions of, and historical debates over, the meaning(s) of "population," trace back the contemporary emphasis on populations as statistical rather than substantive entities to Adolphe Quetelet's powerful astronomical metaphor, conceived in the 1830s, of l'homme moyen (the average man), and argue for an alternative definition ...